一种面向云边端系统的分层异构联邦学习方法
时间:2023-02-21 12:25:07 来源:千叶帆 本文已影响人
钟正仪 包卫东 王 吉 吴冠霖,2 赵 翔
1(国防科技大学大数据与决策实验室 长沙 410003) 2(军事科学院 北京 100089)
传统的云计算模式下,云计算中心部署了大量稳定的高性能计算设备,移动手机等终端需要将收集到的数据传输到云进行计算,最终得到由云反馈的结果.然而,随着人工智能、物联网等新兴技术的发展,终端的数据呈海量爆发式增长,为云、端之间的通信链路造成不可负担的传输压力;
同时,对于无人驾驶等需要实时反馈的计算任务,遥远传输距离带来的时延将会带来不可估量的损失.由于终端设备体积、资源的可得性等限制,难以独自完成复杂任务的计算,基于此,将云算力下沉、终端算力上移汇聚为边缘算力成为解决上述问题的一种理想方式[1].在云边端框架下,原本全部部署在云的模型,分层部署到了云、边、端,使得简单任务能够在边缘甚至终端层级就能完成,这大大减少了计算时延、缓解了通信压力.对于上述分层智能模型而言,一个重要特征就是要具备演化能力,然而模型的演化往往基于大量数据,因此对于云端和边缘模型的演化,需要上传大量的终端数据,直接导致终端用户的隐私泄露.
为了保护用户隐私、最大化将数据控制在用户终端层面,近年来,联邦学习(federated learning, FL)成为了一种热门的面向隐私安全的分布式计算方法.在联邦学习方法下,假设同一个服务器下各个客户端的模型架构相同,各客户端仅需利用本地数据对模型进行训练,用训练后的模型参数取代数据上传到服务器进行聚合,即可以得到一个全局统一的模型,实现多节点的信息融合.因此,本文考虑在云边端分层框架下引入联邦学习方法实现该框架下各个节点智能模型的演化更新.然而,传统联邦学习存在严格的限制:1)客户端资源无差异,各个客户端都具备训练同样复杂度模型的能力;
2)模型全部部署在客户端,为单层的联邦学习;
3)客户端有大量的标签数据供本地模型训练.这些限制直接制约了联邦学习在云边端分层框架的应用:在云边端框架下,一方面,各计算节点由于所处环境、硬件参数不同,在计算、存储、通信等资源上存在较大差异;
另一方面,在模型分层部署的情况下,单层的联邦学习不足以满足所有节点模型演化的需求;
此外,客户端由于人力成本等因素,存在大量无标记数据.
特别地,针对上述联邦学习的异构问题,Li等人[2]通过在本地损失函数中加入正则项的方式,有效避免了本地训练模型的过拟合,一度成为异构联邦学习领域经典的学习方法;
Diao等人[3]能够在不改变模型层数的情况下,横向降低模型宽度从而实现异构联邦学习.但上述训练方法只能得到全局统一的单出口模型,难以满足云边端的模型分层部署要求.
因此,本文面向云边端框架下分层联邦学习、终端资源异构和大量无标签数据3个问题,提出一种面向云边端的分层异构联邦学习方法,将多分支模型分层部署到云、边、端各层级,每一层对应一个或多个出口,用于实现快速推理.在智能模型的训练阶段,采用边缘和云2个级别的双层联邦学习,促进各个节点的协同训练;
在边缘层的联邦训练中,考虑到终端的资源异构情况,为终端定制个性化模型,提高其训练参与度;
同时,针对终端存在大量无标签数据问题,设计半监督学习方法,有效整合无标记数据特征,最终实现云边端系统在水平和垂直方向上多个异构节点的信息融合.
本文的主要贡献有3个方面:
1) 提出了新的异构联邦学习方法.该方法从多分支模型出发,将全局统一模型拆分为适配不同客户端资源的子模型序列,提高了客户端参与度和资源利用效率.
2) 创新了上述异构联邦学习方法下的半监督学习方法.以服务器少量标签数据训练的模型为依托,对客户端无标签数据进行标记并训练,使得最终模型能够有效整合无标签数据特征.
3) 将联邦学习应用于模型分层部署的云边端系统.打破了传统的单层联邦学习限制,为云边端系统开展分布式计算提供了新思路.
联邦学习最初于2017年由Google公司提出[4].在该框架下,服务器将全局统一的模型分发到各个客户端进行本地训练,待训练结束后上传模型参数到服务器聚合得到全局模型,从而实现多节点的协同训练.因为联邦学习能够将用户数据保留在本地进行模型的更新训练,极大地保护了用户隐私安全,近年来受到了学术界和工业界的广泛关注[5].当前,在学术界,主要针对联邦学习4个关键性问题展开研究:通信效率、隐私安全、统计异构和系统异构.针对通信效率问题,尽管联邦学习利用上传模型参数代替了原始数据,但是对于手机等带宽十分有限的移动设备,如何对模型进行压缩提高通信效率仍然是一个亟待解决的问题,当前主要采取的方式有提高客户端更新次数[6]、选择部分客户端参与迭代[7]以及模型压缩[8].针对隐私安全问题,保护隐私是联邦学习提出的首要动因,目前有学者将其与差分隐私[9]、安全聚合[10]等技术结合,进一步加强了联邦学习的隐私保护能力.在工业界,联邦学习除了被Google采纳,Apple公司还将其应用到iOS 13中快捷键盘和“Hey Siri”[11]的语音分类器等应用程序;
在金融领域,微众银行将其应用于洗钱检测[12];
在医学领域,其还可被用于新型肺炎患者氧气需求预测[13]和医学图像[14]分析等.针对统计异构问题,由于现实场景下客户端之间的数据往往来源于不同分布,因而呈现出客户端倾斜现象,削弱了本地更新的效果[5].针对系统异构问题,由于客户端装配的设备面临的环境不同,可能导致客户端之间资源水平差距明显,能够训练的模型复杂度上限不同,需要针对客户端情况定制个性化模型[3].文献[3]通过降低隐藏层宽度的方法构建了适配于不同设备的不同复杂度的模型,文献[15]提出了一种能根据资源状况对客户端进行管理的联邦学习协议.一些学者还提出了异步联邦学习的方法[16-17].本文主要着眼于云边端联邦学习中系统异构问题展开研究.由于文献[3,5-10,15-17]得到的模型为全局统一的单出口模型,难以在云边端框架下分层部署,且主要针对卷积神经网络模型,使用范围有限,因此,本文拟设计一套可适用于多种类模型的、同时易于分层部署的异构学习方案.
此外,针对云边端分层联邦学习的研究,文献[18]将联邦学习应用到云边端多层级分布式计算当中,实验证明分层的联邦学习不仅可以达到较高的准确率,而且能加快收敛速度.但是,文献[18]中仅将模型全部部署在终端,未对模型在云边端分层部署的联邦学习方法展开研究.据我们所知,当前,对联邦学习的研究主要集中在单层联邦、基于终端有标签数据,面向云边端系统的双层联邦研究仍然较少.因此,本文面向模型分层部署的云边端系统,从各个分布式节点资源异构的现状出发,利用终端无标签数据,就如何实现分层联邦学习展开研究.
2.1 联邦学习
传统的联邦学习框架包含一台中央服务器和大量客户端,用于计算的智能模型部署在客户端,通常由客户端进行模型的训练和推理任务,服务器扮演着模型参数聚合者的角色.以最常见的聚合方法FedAvg[4]为例,整个联邦学习过程分为4个阶段:
1) 模型下载.每一轮联邦训练前,被激活的客户端需要从服务器端下载本地模型的参数β并加载到本地模型.
2) 本地训练.基于下载模型,各个客户端利用本地数据对该模型进行更新.假设共有N个客户端,学习率为η,F为损失函数,βi和Fi分别为第i个客户端的模型参数和损失函数值,∇Fi(βi)为模型梯度.那么,本地模型采用梯度下降法进行训练过程表示为
βi=βi-η∇Fi(βi),i=1,2,…,N.
(1)
3) 模型上传.待本地训练一定次数或模型达到一定精度后,客户端将参数上传到服务器进行聚合.
4) 模型聚合.服务器根据各个客户端数据量对上传的参数进行加权平均,得到聚合后的模型参数
(2)
其中,Di为第i个客户端的数据量.将N个客户端的参数值βi以数据量Di与全局数据量的占比进行加权平均后,得到全局统一的模型β.至此,一轮联邦学习结束,以上过程反复迭代,直到达到预设的迭代次数或模型精度.然而,上述聚合方法要求客户端模型统一,在本文提出的异构方法下,各个客户端模型深度不同,这对传统的模型聚合的方法(式(2)所示)提出了挑战.因此,本文对聚合方法进行了创新,将其分为同构聚合和异构聚合2个阶段,最终实现异构模型之间的聚合.
2.2 多分支模型
多分支模型由Teerapittayanon等人[19-20]提出,通过在深度模型中插入提前退出分支的方式实现快速推理.该模型的一个潜在假设是,样本从某一分支提前退出所消耗的计算量小于从后续任一出口退出所消耗的计算量.
在模型的训练阶段,当前主要有2种训练方式:1)模型的主干和分支出口协同训练;
2)分开训练.协同训练时,采用加权损失反向传播机制,即以各个出口退出的样本量占总样本量的比例为权重,计算各个出口对应的损失及梯度,采用随机梯度下降法对模型进行更新.当主干和分支分开训练时,常采取知识萃取的技术,先训练最后一个出口,再以最后一个出口为教师模型对其他出口进行训练.
在模型推理阶段,针对退出模型的判断机制,当前主流的退出方式有2种:
1) 阈值退出法.与Branchynet[19]相似,采用熵作为判断计算结果能否退出模型的依据,以分类任务为例,熵定义为
(3)
其中,C表示所有的分类种类,yc表示样本为类别c的概率.当某一出口处的熵值小于设定阈值T时,认为在该出口处的计算结果足够可靠,可以提前退出网络,反之则不能,需要进入更深一层的网络进行计算.
2) 比例退出法.即训练结束后,根据每个分支的测试准确率占所有分支准确率之和的比例确定样本退出的比例.若全局模型有K个分支出口,每个出口的测试准确率可以表示为acci(i=1,2,…,K),那么每个出口退出样本数占全局样本数的比例pi为
(4)
3.1 分层异构联邦学习
在云边端分层框架下,云端和边缘通常被认为具备充分的资源保障任务计算的顺利开展,然而终端节点可能因为所处环境、硬件参数的差异,在计算资源、通信资源、存储资源存在较大差距.例如在战场环境下,出于隐蔽目的,部分节点由于处于低洼地带导致通信不畅;
部分节点因受到敌方打击导致计算资源、存储资源遭到部分摧毁.而上述资源正是保证智能模型演化的重要支撑,在传统的联邦学习框架下,往往是将一个全局统一的模型分发给被选中参与训练的客户端,极容易出现模型和资源不匹配导致客户端训练失败的现象.因此,有必要设计一种异构的联邦学习方法,提高客户端参与度,有效利用客户端资源.
基于2.2节中所述多分支模型,在深度学习背景下,考虑到不同分支与分支前的主干网络天然构成一个可以独立完成训练和推理任务的完整子模型,且因分支在主干模型中插入的深度不同,不同分支对应的子模型构成的序列天然为一个不同复杂度的模型序列.模型复杂度越大,消耗的计算资源、存储资源、通信资源越多,因此,本文考虑通过在深度模型中间插入分支并将其拆分为分支子模型的方式,构建适应不同客户端资源状况的子模型,尽可能使得联邦学习过程中被选中的客户端都能有效利用本地资源进行训练.本文中的主要符号说明如表1所示:

Table 1 Annotations of Main Symbols
在本文的云边端分层框架下,首先在全局深度模型中间插入2个提前退出分支(分别为图1中的出口2、出口3),作为模型分层部署的切分点.其次,为解决终端节点资源异构问题,在终端模型(出口2及之前的模型)中间插入一个提前退出分支(出口1),用于对终端模型的拆分.以图1中的拆分为例,全局模型共有4个出口分支,在出口2、出口3进行切分,出口1、出口2与其主干网络构成的模型部署在端,出口3与之前的主干网络构成的模型部署在边,所有出口与整个主干网络构成的模型部署在云.由于端模型具有2种出口,可以拆分为2种不同复杂度的模型,由此可以构成二级异构.因此,在该框架下,终端模型之间存在异构现象,各个边缘的模型为同构模型,每个边缘下有多个终端,假设同一边缘下的终端簇中包含终端所有的异构模型种类.
在本文提出的方法中,我们假设,终端存在大量无标签数据,边缘和云端存在少量标签数据.具体的训练过程(见算法 1)可以分为边缘联邦、云端联邦以及云端训练3个阶段.在边缘层次的联邦阶段(行①~),各边缘将终端两出口模型(出口1和出口2)拆分为异构单出口模型(仅含出口1或出口2)并分发给其下适配终端;
待终端本地利用无标签数据训练E1次后,上传到各自边缘聚合为两出口模型(行⑨);
最后,边缘利用本地标签数据对其进行微调(行),得到新一轮的终端两出口模型,如此训练T1次.在云端层次联邦阶段,各边缘首先利用前一阶段边缘联邦得到的终端两出口(出口1+出口2)模型参数初始化边缘模型中对应的主干部分(行~);
再基于本地标签数据,训练由出口3与其之前的主干网络构成的单出口模型E2次;
最后,各边缘将训练得到的本地和终端整体模型上传到云聚合,如此迭代T2次,得到出口3及其主干模型的参数.在云端训练阶段,云利用前一阶段得到的模型主干参数初始化本地模型对应的主干部分(行),再基于云端有标签数据,对所有主干和出口进行整体训练E3次得到全局模型参数.

Fig. 1 The framework of hierarchically heterogeneous federated learning for cloud-edge-end system图1 云边端系统分层异构联邦学习框架
算法1.分层异构联邦学习
输入:边缘数量N、学习率η、边缘联邦次数T1、云端联邦次数T2、终端本地训练次数E1、边缘本地训练次数E2、云端本地训练次数E3;
输出:全局模型参数W.
① for 边缘i=1,2,…,Ndo
/*各边缘联邦*/
② 边缘预训练终端多出口模型;
③ for 边缘迭代次数t1=0,1,…,T1-1 do
④ 边缘i拆分并分配异构子模型到各终端;
⑤ for 边缘i下终端j=1,2,…,nido
⑥ for 终端训练次数e1=0,1,…,
E1-1 do


⑧ end for
聚合;
⑩ end for
/*云端联邦*/
部分;
do
η∇Li(t2,e2);

(5)
(6)

(7)

本节前述内容展示了仿真实验的过程.值得注意的是,在现实分布式场景下,边缘和终端设备往往执行分布式的并行计算.因此,将大大降低算法1的时间复杂度.此外,在每一轮联邦学习过程中,客户端本地训练的次数E1,E2通常较小(≤20),从而降低了对边缘和终端计算资源的要求.
3.2 半监督联邦学习
考虑到人工成本等因素,直接产生数据的终端往往存在大量未标记数据,为了有效利用无标签数据.本文在3.1节所述的边缘联邦阶段设计了一种半监督联邦学习方法.

(8)

图1所示的云边端分层框架可分为纵向节点信息融合和横向节点联合学习2个层级的方法.针对云边端纵向节点信息融合的过程,依次执行边缘联邦、云端联邦和云端训练3个步骤.以上3个步骤层层递进,模型不断加深,每一阶段的学习都利用上一阶段的学习结果对本阶段模型的对应部分进行初始化,并基于此进一步训练.每一阶段的训练过程都采用加权平均法FedAvg进行联邦训练,其收敛分析见文献[5].针对横向节点联合学习过程,由于终端模型存在异构现象,不适用于传统的联邦学习收敛性分析.因此,本文主要就终端异构联邦学习的收敛性进行分析.
我们将整个异构模型的聚合看作主干聚合和分支聚合2部分,下面将分别就主干聚合和分支聚合的收敛性进行分析.首先针对主干聚合,若全局网络共有K个分支,那么整个主干网络将被分支切分为K个部分并依次构成主干模型序列,分别为{ωi(1)(t1),ωi(2)(t1),…,ωi(k)(t1),…,ωi(K)(t1)},其中i表示第i个边缘,ωi(k)(t1)表示全局主干网络中第k个出口和第k-1个出口之间的模型.主干模型之间分别为输入和输出的关系,例如,ωi(1)(t1)的输出为ωi(2)(t1)的输入,ωi(K)(t1)的输入为ωi(K-1)(t1)的输出.我们考虑采用归纳法证明主干模型的收敛性,因此可以将主干网络收敛性的证明分解为2个问题:
问题1.当k=1时,对应的主干子模型收敛,即ωi(1)(t1)收敛;
问题2.当k>1时,ωi(k-1)(t1)收敛时,ωi(k)(t1)也收敛.
证明前,我们先进行5个假设.
假设1.被分解后的每部分主干网络ωi(k)(t1)都可以独立完成模型的训练推理任务,且前一部分主干网络的输出为后一部分网络的输入.



其中,x和y为随机变量.
假设4.边缘i下客户端j的随机梯度的均值和方差满足关系:
假设5.边缘i下客户端j与边缘聚合梯度的二范数存在上限:
首先,我们证明问题1中ωi(1)(t1)的收敛性,当ωi(1)(t1)收敛时,应满足公式:
(9)
其中B1为上限值,若该值随着异构联邦迭代次数T1的增加逐渐降低,则意味着出口1前的主干模型参数随着迭代次数的增加不断接近全局最优解,实现收敛.ωi(1)(t1,e1)为第t1次联邦过程中各个客户端第e1次本地训练的平均模型参数,为了实现出口1前主干模型ωi(1)的收敛,需要满足2个条件:

(10)


(11)
其中F(t1,0)为第t1次联邦学习开始前所有的历史信息.
条件1为中心式学习场景下实现模型收敛的条件;条件2则基于条件1的基础上,考虑到分布式场景,限制了各个客户端模型参数的变化的方差.通过分析,可以得到2个引理:


(12)
(13)
上述2个引理的证明详见附录A和附录B,结合式(12)和式(13)可以得到结论:
(14)

针对问题2中链式收敛问题,当ωi(k-1)(t1)收敛时,ωi(k)(t1)也收敛.因此,在ωi(k-1)(t1)收敛的前提下,当ωi(k-1)(t1)输入给定时,ωi(k-1)(t1)的输出确定.由于在假设1中,各部分主干网络呈输入输出关系output(ωi(k-1)(t1))=input(ωi(k)(t1)),那么可以得到当ωi(k-1)(t1)收敛时,ωi(k)(t1)的输入确定.此时,若要实现ωi(k)(t1)收敛,则存在上限Bk,使得:
Bk,
(15)
其中若Bk随着迭代次数的增加而降低,则实现ωi(k)(t1)收敛,其分析过程与ωi(1)(t1)相同,此处不再赘述,问题2得证.
因此,我们得到:1)当k=1时,ωi(k)(t1)收敛;
2)当ωi(k-1)(t1)收敛时,ωi(k)(t1)收敛.由归纳法可得,主干网络中的每一部分均收敛,最终整个主干网络收敛.
针对分支收敛性的证明,由于单类的分支网络仅存在于一种异构客户端簇下,在联邦学习过程中仅参与同构聚合,这与传统的联邦学习过程一致,具体收敛性分析过程参见模型ωi(1)(t1)的收敛性分析.
5.1 实验设置
在实验部分,我们将以Lenet卷积神经网络的变体为模型,分别在MNIST和FashionMNIST数据集上进行验证,如图2所示.验证模型包含4个退出出口,第1,2两个出口及之前的模型部署在终端,第3个出口及之前的模型主干部署在边缘,最后一个出口及其之前的模型部署在云端.2组数据集均含有60 000张训练图像数据和10 000张测试图像数据.由于本文面向云边端分布式场景,因此构建了由1个云、5个边缘和250个终端构成的分布式框架,其中每个边缘包含50个终端.在边缘层次的联邦学习中,每一个边缘下将有10个终端被随机选择参与训练;
在云端层次的联邦学习中,将有3个边缘被随机选择参与训练.

Fig. 2 Multi-exit convolutional neural network图2 多出口卷积神经网络
考虑到半监督学习场景,本文将60 000张训练数据集做如下分配:随机选择1 000张有标签数据分配给云端;
随机选择5 000张有标签数据平均给各个边缘,每个边缘分别拥有1 000个训练样本;
剩下的54 000张为无标签数据,按数量平均分配给250个终端节点,每个终端分别拥有216个训练样本.实验将分别在独立同分布(independent and identically distributed, IID)和非同独立同分布(non-IID)两种情形下进行检验,针对独立同分布,本文在边缘和终端分配样本的过程中都进行随机均匀地分配,以实现样本在各个终端之间、边缘之间独立同分布.针对非独立同分布,在边缘数据的分配过程中,首先将边缘5 000张样本按照标签顺序依次排列并平均切分为20部分,每部分包含250张图片,每个边缘从中随机选取4部分,形成边缘节点数据之间的非独立同分布;
终端节点的数据分配方法与之相同,将排序后的54 000个样本分为750部分,250个终端随机从中选取3部分作为本地样本.综上,形成了边缘和终端2个层次的非独立同分布.
实验中采用SGD作为训练优化器,MNIST数据集的学习率为0.01,FashionMNIST数据集的学习率为0.05,在每一轮联邦学习过程中,客户端更新次数为20.为了分别研究异构联邦学习方法和分层联邦学习方法的可行性,本文将在这2种分布情形下分别进行验证.同时,本节实验还将验证异构联邦学习方法在资源利用效率上的提升.
5.2 异构联邦学习方法研究
本节将在终端和边缘数据均为独立同分布和均为非独立同分布的2种情形下,对异构联邦学习方法进行研究.对比框架为近年提出的异构学习方法FedProx[2]和同构学习方法FedAvg[4],与本文方法不同的是,以上2种方法在各个边缘向终端分配模型时,每个终端都收到同样的模型,该模型由出口2及其之前的主干网络构成.为了实验的公平性,在2种对比的联邦学习方法中,仍采用本文提出的半监督学习方法对模型进行训练.由于边缘之间在数据处理、训练模型、学习方法上没有明显区别,为了使结果展示更加简洁直观,本文仅从所有边缘中挑选部分进行展示.
5.2.1 独立同分布
图3和图4给出了在MNIST和FashionMNIST数据集下,不同边缘的异构联邦学习和同构联邦学习训练得到的模型效果对比折线图.其中实线为通过本文提出的联邦学习方法得到模型的准确率;
长虚线为传统的同构联邦学习方法FedAvg训练得到模型的准确率;
短虚线为FedProx得到的模型准确率.总体而言,无论是针对MNIST还是FashionMNIST数据集,本文提出的异构方法学习得到的模型准确率收敛值整体优于FedAvg和FedProx.其中,MNIST数据集下,本文方法收敛值比FedAvg提升约4%,比FedProx提升约3%;
FashionMNIST数据集下,本文方法平均可以达到86%,而FedAvg和FedProx平均收敛值均为80%左右,二者相差约6%.但是,值得注意的是,从折线的走势和波动幅度来看,FedAvg和FedProx方法下模型的收敛速度和收敛平稳性更佳,这一点在FashionMNIST数据集上体现更为明显.

Fig. 4 Performance of different heterogeneous methods when FashionMNIST is IID图4 FashionMNIST独立同分布时不同异构方法 的表现
针对本文提出的联邦学习方法收敛值更优的问题,本文通过在一个完整的深度模型中间插入分支的方式,构建出复杂度更小的适配资源紧张终端的子模型.在本地学习阶段,各个终端仅需利用本地数据对本地子模型进行训练更新,无需考虑后续模型的参数对本地训练损失的影响.降低正常大模型更新过程中模型前后的耦合性,一定程度上增大了整个终端全局模型的搜索空间,从而能够在更大空间内找到最优模型.
针对本文提出的联邦学习方法收敛速度更慢和收敛平稳性更差的问题,在同一轮迭代过程中,不同深度的子模型因为自身模型特征限制,能够达到的最高准确率不相同.由于本文方法中终端模型既有出口1对应的子模型,又有出口2对应的子模型,而其他方法下仅有出口2对应的子模型,因此本文方法在收敛进程上存在较差的模型对较优模型拖累的现象,从而减缓收敛进程,增大波动幅度.
5.2.2 非独立同分布
当终端大量的无标签数据和边缘少量带标签数据都呈现出非独立同分布时,5.2.1节中的结论仍然成立,如图5和图6所示.在MNIST数据集下,本文方法的平均准确率约为60%,且不同边缘之间的模型收敛值差距小于5%,与FedProx基本持平;
而FedAvg的平均准确率约为40%,且不同边缘之间的收敛值差距大,受数据分布不均衡的影响,收敛值相差最大的边缘甚至可以达到20%.在Fashion-MNIST数据集下,本文方法的平均准确率约为50%,且不同边缘之间的模型收敛值差距最大为15%;
FedAvg的平均准确率约为40%,最大收敛值之差为20%;
FedProx的平均准确率也在40%左右.由此可以看出,通过插入分支实现的模型异构可以让学习在更广阔的的空间内搜索,这在一定程度上可以补足由数据异构带来的缺陷.

Fig. 5 Performance of different heterogeneous methods when MNIST is non-IID图5 MNIST非独立同分布时不同异构方法的表现

Fig. 6 Performance of different heterogeneous methods when FashionMNIST is non-IID图6 FashionMNIST非独立同分布时不同异构方法 的表现
5.3 分层联邦学习方法研究
针对分层联邦学习的研究,对比框架分别为无联邦学习(也可称为“本地学习”)和仅边缘层级的联邦学习.在无联邦学习的情况下,各个节点仅在“云边端”垂直结构上进行协同学习,终端节点之间、边缘节点直接不再进行协同的联邦学习.因此,为了保证单一节点能在垂直方向上学习得到完整模型,在同一层节点之间不应存在模型异构问题,即终端上全都部署出口2与其之前的主干模型构成的子模型,边缘上全都部署出口3构成的子模型.各个终端通过与对应边缘交互进行半监督学习得到本地出口2模型;
待本地训练完毕后上传至边缘初始化边缘模型对应部分,各个边缘随即利用本地标签数据对初始化模型(出口3对应的模型)进行训练;
接着,将训练完毕的边缘模型上传至云端初始化云端模型对应部分;
最后,云端利用本地标签数据对边缘初始化的模型进行训练得到最终模型.仅边缘层级联邦学习的情况下,模型部署方式与无联邦学习框架相同,此时模型在终端之间同构.不同之处在于,同一边缘下的终端在本地学习之后要上传模型到对应边缘进行聚合,迭代多次得到终端模型,而不仅仅是本地学习.
5.3.1 独立同分布
图7和图8分别展示了在独立同分布情形下不同联邦学习方式的模型表现.横轴表示迭代次数,纵轴为不同学习框架,颜色深浅变化反映了模型表现的变化情况.如右侧标尺所示,颜色越深代表模型的准确率越低,颜色越浅则准确率越高.从图7和图8中可以看出,无论是针对MNIST还是FashionMNIST数据集,双层联邦学习得到的模型在收敛值、收敛速度以及收敛稳定性方面均具有明显优势.在MNIST数据集中,采用"边缘+云端"双层联邦学习方法训练的模型仅迭代不到10次,热力图的颜色变化就趋于稳定,模型达到收敛;
而采用单层联邦学习或无联邦学习,则需要迭代30余次.在FashionMNIST数据集中,采用双层联邦学习的方式不仅在收敛速度上更快,而且从颜色的深浅变化来看,双层联邦学习的曲线更平稳.

Fig. 7 Performance of different federated learning frameworks when MNIST is IID图7 MNIST独立同分布不同联邦学习框架的 模型表现

Fig. 8 Performance of different federated learning frameworks when FashionMNIST is IID图8 FashionMNIST独立同分布时不同联邦学习 框架的模型表现
这是因为,相较于单层联邦学习和无联邦的本地学习而言,在“边缘+云端”双层的联邦学习方法下,边缘和云端的联邦能够定期将各个终端、边缘本地训练的模型特征进行整合,使得最终得到的全局模型综合了各个分布式节点的数据特征.不仅提高了直接表现为测试准确率的模型泛化能力,而且加快了模型的收敛速度.
5.3.2 非独立同分布
与独立同分布情形相同,在非独立同分布情形下,“边缘+云端”的双层联邦学习仍然在收敛值、收敛速度、收敛平稳性上展现出绝对的优势,如图9和图10所示.在MNIST数据集下,模型迭代约10次时达到收敛;
而在单层和无联邦情形下,需要迭代近60次.在FashionMNIST数据集下,虽然在收敛速度上的优势略微减小,但在收敛稳定性上展现出了绝对优势.

Fig. 9 Performance of different federated learning frameworks when MNIST is non-IID图9 MNIST非独立同分布不同联邦学习框架的 模型表现

Fig. 10 Performance of different federated learning frameworks when FashionMNIST is non-IID图10 FashionMNIST非独立同分布时不同联邦学习 框架的模型表现
5.4 资源利用效率研究
为不同资源状态的终端适配不同复杂度的模型,不仅可以有效提高资源弱势终端的参与率,相比于采用大模型进行同构学习,还可以有效降低整个联邦学习过程中计算、通信以及存储资源的开销.考虑到在各终端数据量相同的情况下,资源开销与数据分布情况相关性较弱.因此,本节将在MNIST数据集呈现出独立同分布的情形下进行实验验证,具体的衡量指标为每一轮迭代过程中所有参与客户端的每秒浮点运算次数之和、传输参数量之和以及模型所占存储空间之和.同时,考虑到FedAvg和FedProx均采用全局统一的客户端模型,按照FedAvg和FedProx这2种方法学习产生的资源开销相当,因此,本节仅将本文方法与FedAvg的资源开销情况作比较.现随机从云边端学习框架中挑选一个边缘,针对其边缘异构和同构学习资源开销情况进行测试,得到如图11、图12、图13所示的结果.
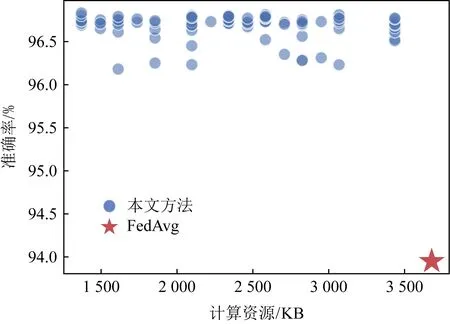
Fig. 11 Accuracy varing with computation resource overhead图11 模型准确率随消耗的计算资源的变化

Fig. 12 Accuracy varing with communication resource overhead图12 模型准确率随消耗的通信资源的变化

Fig. 13 Accuracy varing with storage resource overhead图13 模型准确率随消耗的存储资源的变化
从图11~13可以看出,无论是计算资源、通信资源还是存储资源,通过本文方法学习得到的模型不仅准确率更高,而且消耗的资源更少.准确率高的原因已经在5.2节中进行了说明,消耗的资源更少是因为在训练过程中融入了更多复杂度更低的模型,从而总体上减少了计算资源、通信资源和存储资源的开销.
在新兴的云边端计算范式下,为同时实现用户隐私的保护和模型智能性的稳步提升,联邦学习成为一种热门的面向隐私安全的计算方法,本文就如何在云边端系统下应用联邦学习方法以保护隐私展开研究.具体而言,针对该系统的分层特点,打破了传统单层联邦学习的枷锁,设计了面向云边端系统的双层联邦学习框架,并可拓展至多层联邦学习;
针对由终端设备所处环境、硬件参数不同导致的资源异构问题,提出了异构联邦学习方法,通过在深度模型中间插入提前退出分支的方式,构建适配不同终端资源状态的子模型序列;
针对终端存在大量无标签数据现象,提出了面向异构联邦学习的半监督学习方法,利用服务器预训练得到的适配子模型为终端数据预测伪标签,并基于此对模型进行训练,有效整合了无标签数据的特征.实验结果表明,相比于传统的同构联邦学习方法、单层联邦学习方法以及本地学习方法,本文提出的方法不仅能够在模型准确率上取得明显优势,而且能够显著降低计算资源、通信资源、存储资源的开销.
作者贡献声明:钟正仪负责完成实验并撰写论文;
包卫东提出指导意见并修改论文;
王吉提出算法思路和实验方案;
吴冠霖协助完成实验;
赵翔提出算法思路指导意见.
——稳就业、惠民生,“数”读十年成绩单人民周刊(2022年17期)2022-10-21联邦学习在金融数据安全领域的研究与应用网络安全与数据管理(2022年1期)2022-08-29试论同课异构之“同”与“异”小学教学研究(2022年5期)2022-04-28一“炮”而红 音联邦SVSound 2000 Pro品鉴会完满举行家庭影院技术(2020年10期)2020-12-14303A深圳市音联邦电气有限公司家庭影院技术(2019年7期)2019-08-27多源异构数据整合系统在医疗大数据中的研究电子制作(2019年14期)2019-08-20吴健:多元异构的数字敦煌商周刊(2019年1期)2019-01-31媒体客户端的发展策略与推广模式中国记者(2016年2期)2016-05-25 相关热词搜索:分层,学习方法,联邦,






