多层水驱开发油田采收率快速预测方法
时间:2023-02-21 22:00:05 来源:千叶帆 本文已影响人
侯亚伟,刘 超,徐中波,安玉华,李景玲
(中海石油(中国)有限公司天津分公司渤海石油研究院,天津 300459)
蓬莱19-3是储量十亿吨级特大型油田[1],目前采出程度15.5%,综合含水率82.5%。油层净毛比变化大,非均质强[2],孔隙度15.0%~35.4%,渗透率18~3 619 mD,原油黏度7~46 mPa·s[3],生产压差变化大。影响采收率的因素复杂[4],如何快捷而准确预测不同区块和不同储层的采收率是亟需解决的问题。目前预测采收率的方法有经验公式法[5]、水驱曲线法[6-7]和数值模拟法等[8-9]。采收率预测经验公式未充分考虑非均质性和生产压差等因素,预测可靠性差,适用范围小。水驱曲线法预测的采收率严重依赖生产数据的选取,不同开发阶段的数据反映的规律差异大,直线段不唯一[10],计算结果差异大,实用性差。此外,水驱曲线在特高含水阶段出现“上翘”现象[11-13],拐点和斜率难确定,方法失效。油藏数值模拟法虽然考虑因素全面,但存在动态、静态数据准确提取难度大、计算工作量大和历史拟合不唯一性等问题。
近年来,采用机器学习和人工神经网络(ANN)解决油田开发预测问题取得了一定进展[14-19],但尚未见到综合考虑油藏因素和油井工作制度的ANN预测采收率方法。为此,笔者选取渗透率变异系数、原油黏度、净毛比和生产压差4个关键因素,采用油藏数值模拟方法对625组方案数据进行了模拟,建立了625组采收率及其影响因素关系数据库;
采用基于机器学习的人工神经网络理论,构建了影响采收率的参数输入层、隐含层和输出层,建立了快速预测采收率的人工神经网络方法;
选取500组数据进行机器学习训练,125组数据进行测试检验,采收率预测结果的平均相对误差为0.16%,在精度和计算速度上具有明显优势。
根据蓬莱19-3油田的地质、油藏和流体等数据[1,3],构建了三维模型,网格数量为60×60×7,平面网格尺寸为10 m×10 m;
纵向7层网格由上至下分别对应油组L50、L54、L60、L62、L64、L72和L76,其主要参数见表1。
该油田前期的研究表明,生产压差是影响渗流速度、油井产量、有效泄油面积和最终采收率最显著的动态参数,能较好地反映生产动态。层间渗透率变异系数是层间非均质性的定量表征参数,是影响合注合采多层非均质性油藏层间储量动用差异和采出程度的地质因素;
水的黏度相对变化较小,因此原油黏度是影响油水流度比、含水率和对应含水率情况下采收率的最主要因素;
净毛比定量表征了有效厚度和砂体厚度的比值,能够反映油层的品质和采收率。由此可见,渗透率变异系数、原油黏度和净毛比能较全面地反映油藏特性。因此,选取这4个关键因素,每个影响因素设置5个水平(见表2)。

表1 概念地质模型基本参数Table 1 Basic parameters of conceptual geological model
根据蓬莱19-3油田地层流体性质,原油黏度在5~45 mPa·s 范围内取5个水平值。渗透率变异系数作为反映渗透率非均质性的参数,能够定量表征渗透率非均质程度。考虑油田实际地质情况复杂,储层非均质性强,渗透率变异系数范围大,根据蓬莱19-3油田的非均质特征,渗透率变异系数选取0~1.0之间的5个水平值。净毛比是有效厚度与砂体厚度的比值,根据该油田砂体的净毛比,将净毛比设置为0.6~1.0之间的5个等差水平值。根据该油田单井的实际井底压力变化范围,将生产压差设置为0.7~3.5 MPa之间的5个水平值。此外,基于该油田不同渗透率岩心相对渗透率测试结果,建立并采用了不同渗透率储层相对应的相对渗透率曲线。
将设计的625组数据输入油藏数值模拟软件Eclipse进行模拟,提取采收率及其影响因素参数,建立625组采收率及其影响因素的数据库(见表3)。

表3 采收率及其影响因素关系的数据库Table 3 Database indicating the relationship between oil recovery and influencing factors
采收率预测的神经网络原理见图1,BP算法学习过程分为2步:1)输入影响采收率因素的神经网络权值和阀值,经过隐含层,计算输出值(f代表采收率),实现正向传递[20-21];
2)反向依次对权值和阀值进行修正[22],2个过程反复交替,直到收敛为止。

图1 预测采收率的三层BP神经网络典型架构Fig.1 Typical architecture of three-layer BP neural network predictiong oil recovery
2.1 正向传播原理
如图1中,输入向量为X=(x1,x2,x3,x4),其中4个因素分别代表渗透率变异系数、原油黏度、净毛比和生产压差。
隐含层各神经元的激活值:
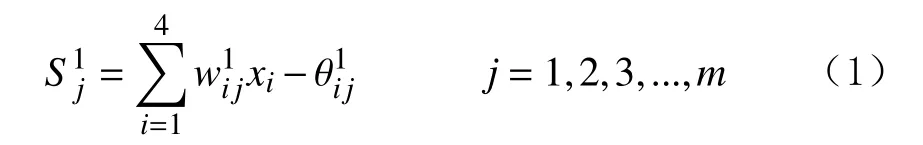
激活函数采用S型的sigmoid函数[23],得到的输出层的输出值:
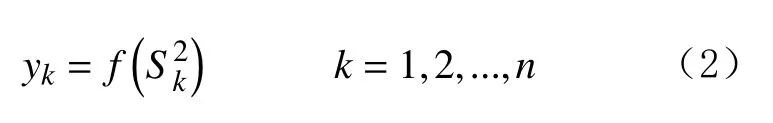
式中:Sj1为隐含层的激活值;
上标l代表隐含层;
下标j代表隐含层节点;
为输入层至隐含层连接权;
i代表第i个因素;
xi为第i个因素的影响采出程度;
为隐含层节点的阀值;
m为隐含层节点总数;
yk为实际输出采收率;
k为输出层节点;
f为输出层隐函数标记;
为输出层的激活值;
上标2代表输出层;
n为输出层节点总数。
2.2 反向传播原理
当计算输出的采收率与期望采收率不一致时要进行校正,校正误差表示为:

隐含层的校正误差为:

网络全局误差为[24]:

当E小于给定精度 ε时,收敛到最优值。只有选取合适的权值和阈值,预测误差才能够快速达到预期,完成整个训练过程。
2.3 收敛优化方法
为了解决神经网络收敛速度慢和局部最小值的问题,需优化神经网络的权值和阈值,获取最优是初始权值和阈值。S. Mirjalili等人[25]提出了一种基于仿生学的群智能优化算法(又称“蜻蜓算法(DA)”),其技术思路来源于自然界中蜻蜓群集的分离、对齐、内聚、寻觅和躲避等5种行为[26],蜻蜓的位置和步长迭代式为:
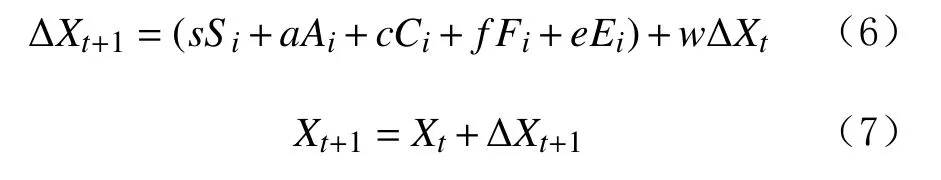
式中:ΔXt+1为t+1代位置更新步长;
a,c,e,f和s分别为对齐、内聚、躲避、寻觅和分离等5种行为的权重系数;
t为当前迭代次数;
w为惯性权重;
Si为第i个体的分离度;
Ai为第i个体的对齐度;
Ci为第i个体的内聚度;
Ei为第i个体对外排斥力;
Fi为第i个体对食物的吸引力;
Xt+1为t+1代种群位置;
Xt为当前t代种群位置。
上述算法解决了局部最优问题,可以得到全局最优解。为了便于快速计算,笔者利用MATLAB工具编制了以上算法的计算程序。
将625组油藏数值模拟方案的模拟结果作为学习样本的来源,提取500组数据用来建立采收率学习样本库(训练集),125组数据作为测试检验样本(测试集),样本库如表3所示。对学习组的每个影响采收率因素对应的样本参数进行归一化处理,处理后数值范围为[0,1];
将归一化参数作为BP网络的参数输入,利用“蜻蜓”群智能优化算法对网络的权值和阈值进行优化;
将优化得到的最优权值和阈值作为BP神经网络中权值和阈值的初始值,对BP网络进行学习训练;
训练结束后,得到最佳的神经网络采收率预测模型DA-BP,然后使用测试检验样本检验DA-BP的预测准确率。
将网络模型计算的采收率和油藏数值模拟计算的采收率进行对比可知,二者所对应的点很好地分布在直线y=x附近(见图2),均方误差为0.48%,相关系数为0.997 4,表明训练精度达到要求。
将125组测试数据的已知采收率值作为横坐标,将DA-BP模型预测采收率作为纵坐标,得到图3。图3表明,经过机器学习和优化得到的神经网络预测的125组采收率与检验数据基本在对角线位置附近,二者吻合较好。蓬莱19-3油田不同岩样试验测定的水驱油效率为62.9%~84.6%,根据该油田的储层物性和流体性质,波及系数取值范围为65.0%~90.0%,计算得到不同小层的采收率范围为40.8%~76.1%,平均为58.5%;
本方法预测的125组采收率范围为40.5%~76.4%,平均为57.3%;
经验公式预测的采收率范围为38.0%~45.0%,可以看出经验公式法预测的采收率明显偏低。
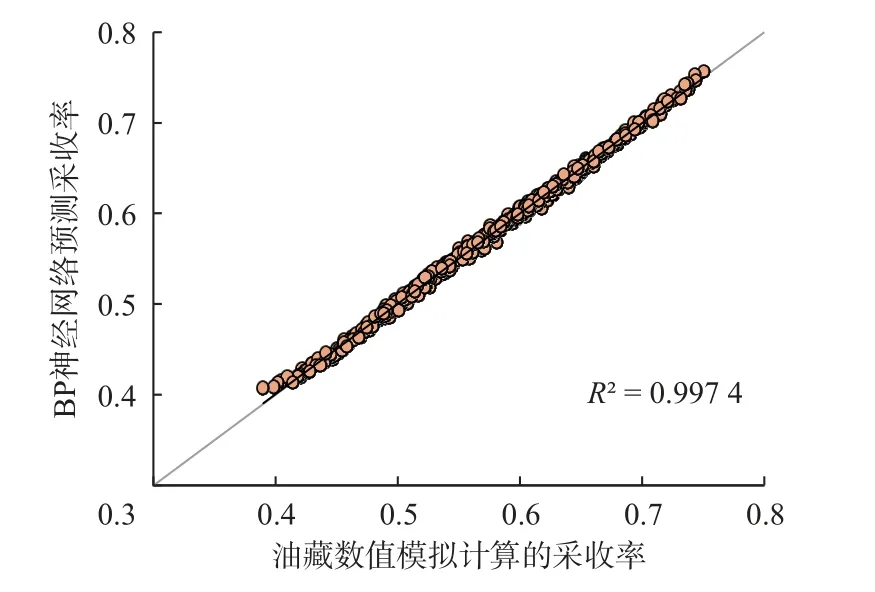
图2 500组训练集的数值模拟采收率与神经网络预测值交会图Fig.2 Intersection of oil recovery values from numerical simulation and neural network prediction (500 groups of data from training set)
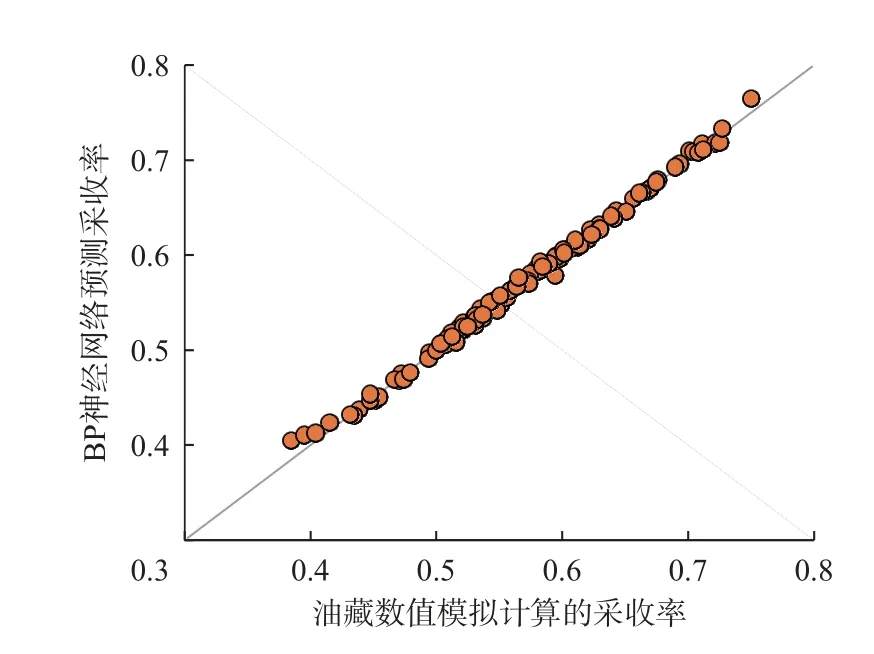
图3 125组测试集的数值模拟采收率与神经网络预测值交会图Fig.3 Intersection of oil recovery values from numerical simulation and neural network prediction (125 groups of data from test set)
125组测试集的预测采收率与数值模拟得到的采收率误差如图4所示。采收率绝对误差(预测采收率减去测试样本采收率)-1.70%~2.00%,均值为0.08%;
相对误差(绝对误差与测试样本采收率的比值)-2.91%~5.08%,均值为0.16%。
预测的采收率相对误差区间的频数如图5所示,误差分布直方图呈近似正态分布,相对误差集中在-1.0~1.0%,占总样本的81.6%,表明经过优化神经网络模型的预测精度较高,能够满足水驱开发油田采收率预测精度要求。

图4 125组测试集的BP神经网络预测结果误差分析Fig.4 Error analysis of prediction by BP neural network(125 groups of data from test set)

图5 预测采收率相对误差分布直方图Fig.5 Relative error distribution histogram of predicted oil recovery
1)引入了反映油井开发动态的生产压差,建立了基于BP网络优化算法的多层水驱开发油田采收率快速预测方法。
2)智能优化算法实现了合适的权值和阈值的初始化,加速了收敛速度,提高了神经网络预测采收率的精度,并解决了局部最小值问题。
3)建立的水驱油田采收率预测方法弥补了采收率预测经验公式法适用范围小,水驱曲线方法直线段选取难度大,数值模拟方法参数多、计算工作量大和历史拟合结果多解性等不足。
4)水驱开发油田采收率预测方法具有快速预测采收率的优势,但训练模型的精度受控于训练样本的质量、数量和来源,建议进一步扩大训练样本的来源和影响因素的参数取值范围,拓宽该方法的适用范围。
猜你喜欢 水驱采收率权值 一种融合时间权值和用户行为序列的电影推荐模型成都信息工程大学学报(2022年3期)2022-07-21《油气地质与采收率》征稿简则油气地质与采收率(2022年3期)2022-05-20水驱前缘测试技术在薄层油藏调驱中的应用复杂油气藏(2021年3期)2021-12-17《油气地质与采收率》征稿简则油气地质与采收率(2021年4期)2021-08-04《油气地质与采收率》第六届编委会油气地质与采收率(2021年4期)2021-08-04《油气地质与采收率》征稿简则油气地质与采收率(2021年3期)2021-06-02基于5G MR实现Massive MIMO权值智能寻优的技术方案研究邮电设计技术(2021年2期)2021-03-13一种基于互连测试的综合优化算法∗计算机与数字工程(2019年11期)2019-11-29浅析BQ油藏开发效果评价装饰装修天地(2019年3期)2019-10-21油田区块的最优驱替开发方式决策:基于全生命周期视角商业会计(2018年9期)2018-09-10 相关热词搜索:收率,多层,油田,





