一种基于风功率曲线的SCADA数据清洗方法研究
时间:2023-02-24 18:00:07 来源:千叶帆 本文已影响人
夏延秋,夏和民,冯 欣
(华北电力大学 能源动力与机械工程学院,北京 102206)
作为一种可再生能源,风能受到诸多国家的重视。随着我国风机装机容量的逐年增加,至2020年,我国风力发电总量占比已达各产业总发电量的第三位,所占比例亦在逐年增加。但越来越多的风电机组运维问题凸显出来。虽然,各风电场引入了SCADA数据采集与监视控制系统对风机进行监测[1],然而诸多情况下,当工作人员发现SCADA系统发出警报再去对风机停机维修时,已经为时已晚,由此导致的损失可能是巨大的。维护风机良好的工作状态是风电场正常运行的首要任务,而高质量的SCADA数据则为分析及预测风机当前状态及未来趋势提供更为真实、有效的数据支持与保障。SCADA数据中风速、风向、环境温度等具有波动性的参量,可使风机的功率、发电量、各种监测温度也具有波动性。风机发电功率是评价风机是否正常工作的一项重要指标,基于风电场的各种数据信息对风机发电功率进行预测[2],可为制定风电并网消纳预案提供重要参考依据。针对SCADA数据展开的分析与研究对风电场及电力系统的可持续发展有深远影响[3]。
诸多研究表明,在用机器学习算法处理SCADA数据时,模型的准确性受异常点的影响较大,因此,针对SCADA数据的有效清洗与识别技术和方法一直是研究的热点。现有的SCADA数据清洗方法各具优势,但也存在不足。文献[4]分别建立基于密度聚类法、截断法、斜率控制法、核密度估计法的异常数据识别模型,实现了风电机组运行数据的定向清洗。文献[5],[6]采用局部异常点检测算法(LOF),仅能识别部分密度值很低的点,当异常值与正常值密度相近时,会被划分为同一簇,无法进行有效识别。文献[7]采用孤立森林对高频SCADA数据(1 s采样一次)进行清洗,虽然在后续深度学习神经网络的功率预测效果更好,但是其对限功率点间的数据清洗效果较差。
作为一种数据清洗识别算法,一类支持向量机(OCSVM)已在诸多领域有所应用。文献[8]采用OCSVM进行信息系统人员基本情况和adult数据集的相似重复数据分类识别检测,效果比支持向量域描述算法和传统二分类支持向量机算法均好。文献[9]基于时间序列的建筑能源消耗图像化,采用OCSVM检测能源消耗的异常情况。文献[10]采用OCSVM对电力质量进行监测,在基于较大正常数据的训练下,模型可以实时检测异常扰动的出现。本文结合风机的实际情况,提出一种改进的OCSVM算法,将其运用在风机SCADA的风功率曲线数据清洗,并通过实例验证了算法的有效性。
风机数据清洗中采用最多的研究对象是风速-功率曲线(P-V图),图1为基于风机SCADA数据的风速-功率曲线异常数据分布特征示意图。将原始的风功率散点图根据其运行状态和分布特征及运行状态分为4类,即正常运行点、停机点、限功率点和异常运行点。
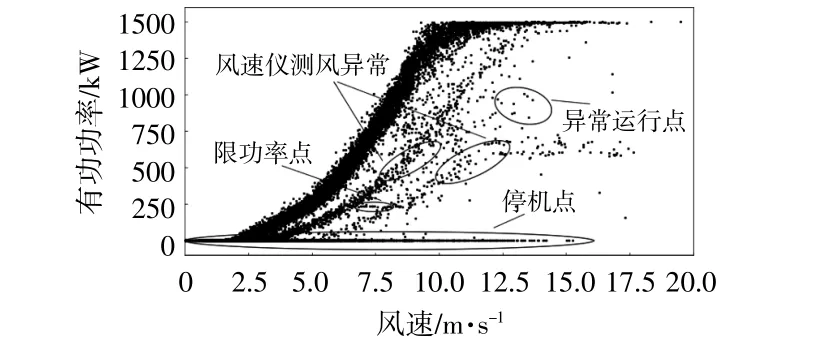
图1 风功率曲线异常数据分布特征示意图Fig.1 Schematic diagram of abnormal data distribution characteristics of wind power curve
简单的异常数据识别模型有基于正态分布的3σ模型等,复杂的异常数据识别模型有基于散点型数据的密度/距离、连线数据的夹角、利用线性/非线性变换进行升维/降维寻找超平面等。OCSVM算法属于后者。有学者将OCSVM视为一种新颖值检测算法,这种方法尚未被用于风机SCADA数据清洗。
2.1 OCSVM异常值检测原理
OCSVM算法是一种半监督学习分类算法,同样适用于正常数据多、异常数据少的情况,且在处理高维数据时效果更好。
OCSVM的计算原理为

式中:ξ为松弛张量;
ν为权衡参数,相当于二分类SVM问题中的C,为超平面的划分提供上下界;
Φ为原始数据集空间到特征空间的映射变换;
w和ρ均为超平面的参数。
引入拉格朗日算子并采用dotproduct calculation,决策函数可变为

式中:α为拉格朗日乘子;
K(x,y)为核函数;
sgn(x)为阶跃函数。

2.2 SCADA异常数据预处理
对东北某风电场的同一批次风机展开研究,发现每台风机都存在大量停机点类型的异常数据,对此类数据的处理一般采用删除发电量小于5的数据点。
对该批次的风机进行风功率曲线可视化处理,发现大部分风机均有限功率点类型的异常数据,需要对这些点进行预处理删除。图2为风机限功率点故障类型图。
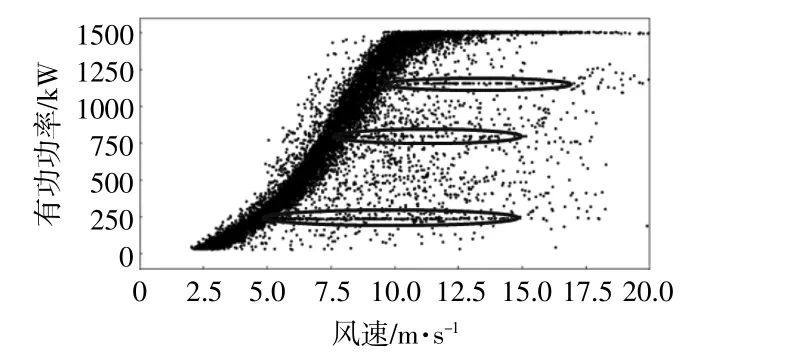
图2 风机限功率点故障类型图Fig.2 Schematic diagram of fault type of fan power limit point
限功率点类型的异常数据可分为三类,本文将图2中标准的异常数据自下而上命名为第一类、第二类和第三类限功率点。资料中很少有对弃风限电导致的限功率点的解释说明,也没有指出风机限功率点的功率范围,为此本文对该风场的同一批次风机的限功率点功率范围进行估算。
图3为该风电场55号风机的限功率点示意图。

图3 第一类限功率点示意图Fig.3 Schematic diagram of the first type of power limit point
该风机只有第一类限功率点,采用区间统计的方法来估算第一类限功率点的功率范围。取风速为5.82~6.32 m/s的数据,获取此风速区间对应功率点的最大值和最小值分别为111.85 kW和702.71 kW,得出此功率区间的长度为590.86(图4)。再将此功率区间以20的单位长度进行区间划分,可被分为30个区间,统计单个区间内点的个数(表1)。由于概率密度的关系,正常数据密度大(表1中区间13~25),其次是限功率点数据(表1中区间6,7),因此可以得出区间6和7内的点为限功率点,其功率为210~250 kW。

图4 风速为5.82~6.32 m/s的风功率散点示意图Fig.4 Schematic diagram of wind power scatter with wind speed of 5.82~6.32 m/s

表1 风速区间为5.82~6.32 m/s的功率点分区间统计Table 1 Corresponding wind speed interval between 5.82~6.32 m/s power point statistics
将此功率范围运用到其它风机进行验算,结果是合理的。同理,在其它风机上运用此方法估算出第二类限功率点的功率为784.18~804.18 kW,第三类限功率点的功率为1 150.58~1 170.58 kW。同理,在有相同故障数据类型的风机上皆可验证算法的准确性。
据此,可按照上述方法得到的限功率点的功率范围对此类型异常数据进行删除。
2.3 改进的OCSVM数据清洗流程
改进的OCSVM是一种针对不同类型风功率异常散点的数据清洗算法,可结合风功率散点本身的特点和预处理及OCSVM的算法优势,从而达到预期目的。数据清洗的具体步骤如下。
①在风场同一型号的全部风机中选择将要处理的风机,选择某几个月的连续SCADA数据。
②根据风机的运行规律,停机点并不包含有用的风机运行信息,可直接删除发电量小于5的SCADA数据点,并得到风功率散点图。
③根据风功率散点图的实际情况,采用2.2节中提出的方法,删除图中出现的第一、二、三类的限功率点。
④根据风功率散点图的分布特点将其一分为二,在风功率散点图中,当风速小于额定风速时,采用基于高斯核的OCSVM清洗这部分散点,另一部分采用基于线性核的OCSVM进行清洗。完成后将两部分合并。
⑤将清洗完的数据运用到后续的风机参数预测中检验清洗效果。
3.1 数据样本选择
东北某风电场二期为双馈型异步发电机,其基本运行参数见表2。

表2 风机基本运行参数Table 2 Basic operating parameters of fans
查看近两年故障统计表,发现有6台风机更换过发电机或发电机双侧轴承。根据异常数据点的类型,选择6台故障机组中的37号、55号、61号和66号4台检验前述算法的清洗识别效果。4台风机更换配件前4,5个月的原始风功率曲线如图5所示。

3.2 数据清洗结果及对比分析
将改进的OCSVM算法运用于上述4台风机的风功率曲线清洗。以风机的额定风速为界限,对该界限左右两侧的风功率散点分别采用基于线性核、高斯核的OCSVM进行清洗,并与四分位法、LOF和IF方法进行清洗效果对比(图6~9)。


图6 37号风机数据清洗结果示意图Fig.6 Schematic diagram of data cleaning result of No.37 fan

图7 55号风机数据清洗结果示意图Fig.7 Schematic diagram of data cleaning result of No.55 fan

图8 61号风机数据清洗结果示意图Fig.8 Schematic diagram of data cleaning result of No.61 fan

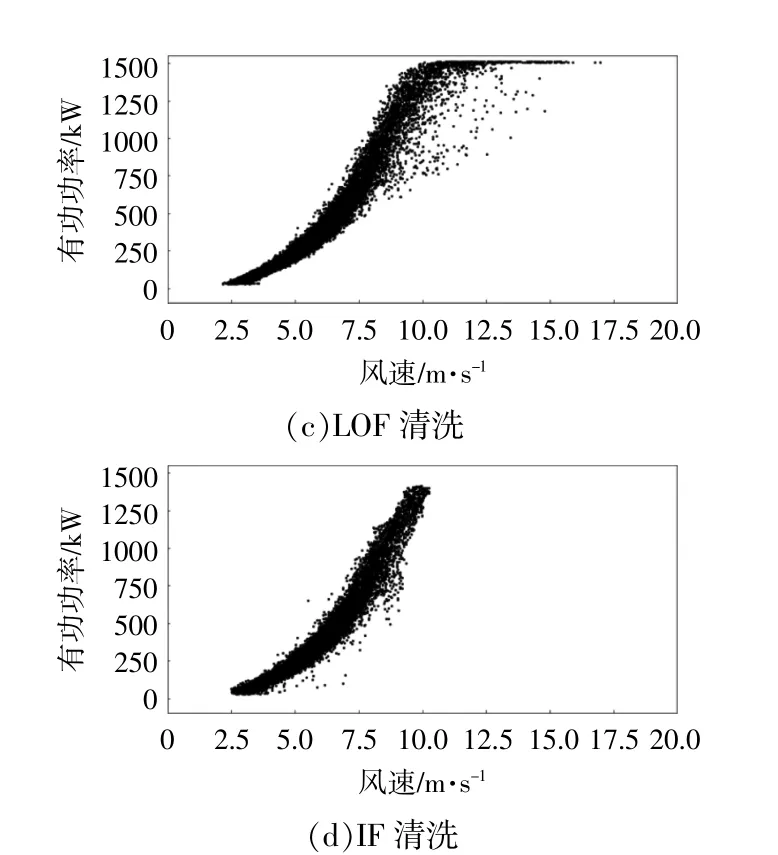
图9 66号风机数据清洗结果示意图Fig.9 Schematic diagram of data cleaning result of No.66 fan
由图6~9可知:预处理-OCSVM的清洗效果均优于四分位法、LOF和IF;
在低风速区段,四分位法清洗后的风功率曲线存在锯齿状边界,在高风速区段,其对异常数据的清洗效果非常差,但此方法对限功率点的清洗效果很好;
对存在限功率点的风机,LOF在限功率点上的清洗效果不好,且对中风速区段的异常点的清洗效果较差,在超高风速区段,其会直接清洗掉全部数据;
IF能清除部分限功率点的异常数据,对非限功率点的数据清洗的效果也不佳,且会将位于中风速、高风速区段的数据全部识别为不正常数据。
3.3 清洗数据对风机性能预测模型影响分析
LSTM模型是循环神经网络的一个变种,常用于基于时间序列模型的预测。均方根误差(RMSE)、平均绝对误差(MAE)和确定系数(R2)是常用的预测模型评价指标。
经测试,清洗后的数据对基于LSTM的风力发电机驱动侧轴承温度的预测效果可以起到促进作用。以66号风机为例,清洗前后的预测模型评价指标变化见表3。由表3可知,清洗后预测精度更高。

表3 数据清洗前后预测评价指标对比Table 3 Comparison table of prediction and evaluation indicators before and after data cleaning
风功率数据曲线的异常数值点会对风机状态评估和性能预测产生负面影响。本文针对风功率曲线散点的分布特征,分析了因弃风限电而产生的限功率点的数值范围,提出了一种改进的OCSVM数据清洗方法,设计和对比验证了整个清洗流程。实例数据测试结果表明,本文所提出的方法能够有效进行异常数据清洗,对异常点清洗效率更高,结果更接近标准风功率曲线,用于后续预测效果更好,具有较好的适用性。
猜你喜欢 散点示意图风速 高速铁路风速监测异常数据判识方法研究铁道建筑(2021年10期)2021-11-08先画示意图再解答问题数学小灵通(1-2年级)(2020年9期)2020-10-27利用Lorenz RR 散点图快速诊断急危重心律失常昆明医科大学学报(2020年7期)2020-08-31高血压个体家庭连续自测收缩压特征描述与分析南京医科大学学报(社会科学版)(2020年2期)2020-05-13人定胜天人物画报(2020年33期)2020-03-14黔西南州旅游示意图当代贵州(2019年41期)2019-12-132006—2016年平凉市风速变化特征分析现代农业科技(2018年11期)2018-08-14冲击波散点和定点治疗肱二头肌长头肌腱炎的临床观察现代养生·下半月(2017年8期)2017-12-28快速评估风电场50年一遇最大风速的算法风能(2016年11期)2016-03-04“三定两标”作好图中学生数理化·八年级物理人教版(2014年2期)2014-04-02 相关热词搜索:曲线,功率,清洗,





