一种增强少数类边界的多类不平衡过抽样算法
时间:2023-03-01 17:10:06 来源:千叶帆 本文已影响人
曹 兰
(漳州职业技术学院电子工程学院,福建 漳州 363000)
数据挖掘应用所面临的一个相对新的挑战是如何从不平衡的数据集中提取少数类规则。在当前实际应用中,Web挖掘、文本分类及生物医学数据分析等[1-3],它们都面临着少数类的实例数量比多类的实例数量少很多的情形,从而造成了如何在机器学习中准确地识别这些少数类的困难。例如,在金融领域中,怎样在大量交易中发现欺诈性信用卡活动[4-7];
探测卫星图像的溢油[8];
在生物医学数据分析中,与正常的非癌症病例相比,不同类型癌症的数据实例通常非常有限,所以能尽早为患者预测癌症的类型并提供适当及时的治疗非常重要[9]。因此,在数据集中,当某些类型的数据分布显著支配实例空间时,就会发生数据不平衡。如何从不平衡的数据集中提取少数类规则,越来越受到学术界和工业界的关注。
当前处理数据集中不平衡问题主要是抽样方法,该方法主要解决数据集中的类实例平衡问题。目前有两种抽样方法:欠采样和过采样。过采样抽样方法是数据集中少数类,从而使不平衡分布达到平衡状态[10-13]。例如,成本曲线技术被用于研究过采样和欠采样与基于决策树的学习算法的交互作用,该技术研究了将概率估计、剪枝和数据预处理相结合的采样技术用于决策树学习[14-15]。此外,“JOUS-Boost”通过将自适应增强与抖动采样技术相结合的方式来处理不平衡的数据学习[16]。最近的一些研究是基于支持向量机从不平衡数据集中主动学习,这种学习方式不需要搜索整个训练数据空间,而是可以有效地从随机的训练种群中选择信息实例,从而大大降低了处理大型不平衡数据集的计算成本[17]。
以上这些处理数据集中不平衡数据的方法确实起到了一定作用,但都是基于现有数据集上充分利用对实例进行评估、剪枝、选择和计算等来减少样本产生偏差。由于少数类实例数量的局限性,这些处理不平衡方法始终难以突破少数类样本数量本身局限所带来的偏差,且可改进的偏差空间有限。因此,过抽样SMOTE算法[18]通过生成任意数量的合成少数类实例,再将分类器学习偏差转移到少数类,从而通过人工生成数据样本克服原始数据集的不平衡。在该思想的基础上进行扩展的SMOTEBoost算法是合成过程与自适应增强技术相结合,以改变更新权重,从而更好地补偿偏斜分布[19]。为了保证少数类和多数类的最优分类精度,Boost-IM算法通过使用“种子”样本为少数类和多数类生成合成数据示例[20-21]。这种在原数据集基础上为不平衡数据生成合成实例的方法对解决样本偏差提供了另一种思路,并能较好地解决样本偏差问题。但在生成合成实例上没能很好地细分到每一少数类实例,且未能明确区分少数类与多数类的边界,而边界的区分对提高分类准确率是非常重用的。
本文提出一种增强少数类实例边界的多类不平衡过 抽 样 分 类 算 法(MEBMI,a Method to Enhance the Boundary of Minority Instances in the Multi-class Balance)。该算法核心思想是自主地随少数类中样本的K邻近样本的分布情况自动生成合适数量的少数类样本,对于那些与多数类邻近的少数类样本所生成合适数量的合成实例,能够起到进一步区分少数类与多数类的界限的作用。因此,该算法将决策边界自适应地转移到那些难以学习的少数类样本上,同时也减少了因原始不平衡数据分布问题而引入的学习偏差。
1.1 基本定义
设训练数据集D含有m个实例{Xi,Yi}(其中i=1,2,…,m),Xi含有n个属性,对应类标签为Yi。定义ms和ml分别为数据集中少数类与多数类的实例数量。因此,ms≤ml,ms+ml=m。
定义1不平衡数据集中少数类的比率为:d=m s/m l,其中d∈(0,1]。
定义2 生成合成少数类实例数量为:G=(m lm s)×β,其中,β∈[0,1]是合成实例后少数与多数实例的比率。如果β=1,则少数类与多数类实例平衡。
定义3少数类实例的K最近邻数量中多数实例的比率:r i=∆i/K(i=1,2,……,m s),∆i是K最近邻数量中多数实例数量,r i∈[0,1]。
定义4少数类实例的K最近邻数量中多数实例的密度
1.2 算法实现过程
为了通过过采样少数类实例来平衡少数类实例与多数类实例之间的数量不平衡,需要合成一定数量的少数类实例,同时也能加强其边界。本算法步骤是:首先,依据β确定生成合成少数类实例数量(定义2);
其次,统计各少数类实例的K最近邻数量中多数实例的比率(定义3);
再次,计算各个少数类实例的K最近邻数量中多数实例的密度(定义4);
最后,计算各个少数类实例对应生成合成实例数(定义5)。
因此,越靠近边界处,少数类实例的K最近邻所含的多数类实例就越多,故其密度越高,且合成少数类实例也越多。
合成少数类实例算法如下:

1.3 β参数的选取
本算法中测试数据集来自UCI机器学习数据库,具有一定的现实意义。表1详细地描述了数据集的特点,其中数据集abalone、vowel和shuttle中的少数类实例数量明显比多数类实例数量少很多,大概只有多数类实例的1/10,数据集diabetes和spambase中的少数类实例也只有多数类实例实例的1/2左右。

表1 数据集表
图1显示了合成实例后少数与多数实例的比率β值对分类精度的影响,本算法使用基于C4.5分类器的J48决策树算法对表1中的数据集经过10次的交叉验证实验,以少数类样本为正类计算精度,其中K值取为5。由图1可见,当β参数为1时,所有数据集获得了最好的精度,且相对较为稳定。
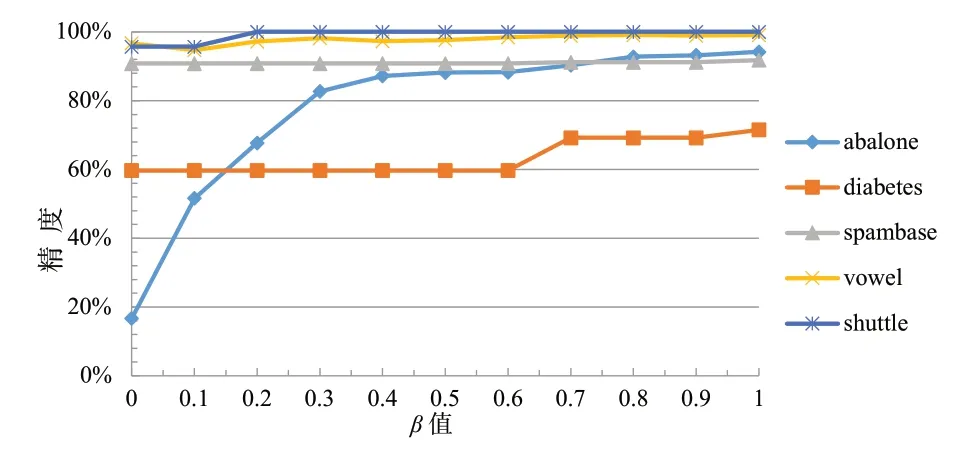
图1 β对于分类精度的影响
在评价分类性能时,评估度量起到了至关重要的作用。对不平衡数据分类的常用评价标准包括AUC、ROC曲线和基于混淆矩阵的度量,比如:查全率、查准率、Fmeasure和G-mean等。表2所示为在两类别情况下,将少数类作为正类,多数类作为负类,通过分类之后,训练集中的实例可分为混淆矩阵的4种情况。

表2 分类器的混淆矩阵

根据表2中的混淆矩阵,可计算出几个度量:F-measure(F1)是查全率和查准率的值的调和均值,其值接近两数的较小者,故而当F1值较大时,说明Recall值和Precisi on值都较大。
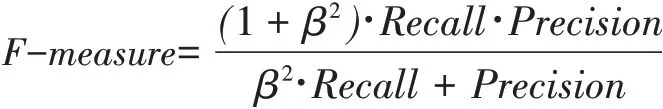
其中,β是用来调整Recall和Precis ion的权重,通常值设为1。
如果同时关注多数类和少数类的性能,即希望负类率与查全率都取得较好性能,则使用G-mean来度量两个的平均性能。

本文将采用OA、F-Measure和G-mean作为评价度量。
所有实验是在Weka平台环境上运行的,选择的实验数据集来自UCI数据集,采用C4.5实现的J48决策树算法对每个组数据集用10-折交叉法验证,采用多种评估算法来评估分类性能。实验参数设置如下:设置β为1,K为5(K值的选择最为困难,需要根据不同的数据集的不平衡度及特点进行选择,此处选择一个对大多数数据集都较为适用的值),不平衡数据集中少数类的比率d设为0.75。
图2显示了在采用MEBMI算法生成合成实例之前与之后的数据集结果,为了便于显示,选取数据集中2个属性进行可视化,图中蓝色代表多数类,红色代表少数类,图2(a)—图2(e)的下部分(过抽样后)代表已采用MEBMI算法,上半部分(过抽样前)代表原始数据集。从图2中可知原始数据集中少数类的数据较为稀疏,特别在多数类数据边界邻近数据的这种稀少性极易引起分类过程的样本偏差,但经过MEBMI算法生成合成实例后,在少数类数据边界上的样例明显增多,且少数类与多数类的边界数据更加经纬分明,从而减少分类时样本偏差。
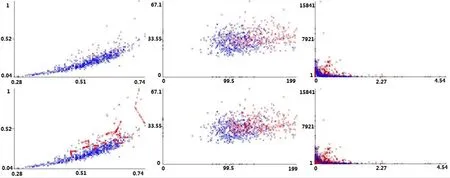
图2 5个数据集过抽样前后对比(单位:个)
图3 (a)—图3(e)显示了采用本算法之前与之后,分别对五个数据集进行分类的情况,从图中可以看出采用本算法后,当数据集中多数类与少数类数据达到一定平衡,并且多数类与少数类的边界数据更加清晰时,在常用的分类评价指标查全率、查准率、F1等明显高于原始的不平衡数据。因此,本算法对分类预测准确率起到了实质作用。

图3 过抽样前后评价指标比较
传统SMOTE算法生成合成实例是建立在两个少数类原始样例的连接线上,并不能很好体现样例的分布情况,特别是在多数类与少数类边界上生成的合成实例有一定的局限性,也不能很好反映少数类实例边界的真实分布。本算法MEBMI在生成合成实例中引入了随机参数,并在合成实例数量上加上了权重系数来强调边界实例的重要性,从而进一步加强了合成实例的真实分布并加固了多数类与少数类的边界界限。
表3所示为本算法与SMOTE算法的评价比较。表3中,在多个不平衡数据评价方法上,通过与传统SMOTE过抽样算法进行比较,MEBMI算法明显优于传统SMOTE算法,特别在F-Measur e和G-mean评价度量上,本算法获得了较高的查全率和查准率,同时也取得了较高的正类率和负类率,即提高了多数类和少数类的分类准确率。

表3 本算法与SMOTE算法的评价比较
实验结果表明,根据每个少数类实例周围的密度情况,添加相应的权重系数,能自动调整生成合成少数类实例数量,且能更加真实体现少数类实例的分布,不但提高了整体准确率,而且提高了多数类及少数类样例的预测能力。
针对传统SMOTE算法在过抽样生产合成实例中存在的一些不足,提出了一种改进的过抽样算法来平衡不平衡数据,在合成实例时引入随机参数,根据少数类实例的密度分布加入权重,既克服了传统SMOTE算法少数类合成实例的固定性质,也能更加真实地区分多数类与少数类边界,使得平衡后的整个少数类实例更加真实有效。实验测试结果表明,在多数类预测评价指标不受影响且有所提高的情况下,确实对少数类样本预测评估指标产生了良性影响,使分类器能更好地减少由数据不平衡带来的误差。
猜你喜欢 查全率实例边界 守住你的边界故事作文·高年级(2022年2期)2022-02-24拓展阅读的边界儿童时代·幸福宝宝(2021年11期)2021-12-21探索太阳系的边界小学科学(学生版)(2021年4期)2021-07-23意大利边界穿越之家现代装饰(2020年4期)2020-05-20海量图书馆档案信息的快速检索方法现代电子技术(2018年20期)2018-10-24基于词嵌入语义的精准检索式构建方法现代情报(2018年11期)2018-01-07完形填空Ⅱ高中生学习·高三版(2014年3期)2014-04-29完形填空Ⅰ高中生学习·高三版(2014年3期)2014-04-29基于Web的概念属性抽取的研究中国管理信息化(2009年10期)2009-06-19 相关热词搜索:抽样,不平衡,边界,





