LAA/Wi-Fi共存时智能竞争信道算法研究
时间:2023-03-10 11:40:03 来源:千叶帆 本文已影响人
周 洋,周 琴,吴楚鑫
(湖北大学 湖北 武汉 430062)
为了满足频谱需求,部署在授权频段上的LTE开始转向非授权频段,Rel-13提出了在未授权频谱上的授权辅助(licensed-assisted access,LAA)技术。5GHz频段上有丰富的频谱资源,但已部署有Wi-Fi技术,因此LAA和Wi-Fi的公平高效共存问题一直在被研究。授权辅助(licensed-assisted access,LAA)引入先听后说(listen before talk,LBT)公平机制,该机制主要是对信道进行监听,当信道显示忙碌时,等待数据传输的节点应该延迟访问进入回退阶段,它需要从竞争窗口中随机选择一个回退时间,在回退阶段结束后再传输数据。Wi-Fi采用与此类似的带有冲突避免的载波侦听多路访问(carrier sense multiple access with collision avoid,CSMA/CA)机制[1],经过一段空闲的分布式帧间间隙(distributed inter-frame spacing,DIFS)后,节点进入回退阶段,当回退时间减少至零时开始传输数据。
为了获得更大的可用带宽和更高的数据传输速率,LAA引入了多载波LBT机,通过聚合多个载波传输数据。该机制有两种类型,类型A和类型B。在类型A中,每个候选载波都需要进行LBT过程,且使用率先完成LBT的载波来进行数据传输,显然在每个载波上进行LBT过程会造成资源的浪费。而在类型B中首先在候选载波中选出一个载波作为主载波在其上进行LBT过程,当主载波上的LBT快结束时,在其他的辅助载波上进行一个快速的CCA过程,然后将主载波与空闲的辅助载波进行聚合来传输数据。Wi-Fi引入了信道绑定技术,信道绑定技术是指在根据选定主信道之后再尽可能地与其他空闲连续信道进行绑定。多信道的传输虽然可以提高数据的传输效率但是也有增加节点之间碰撞的风险,因此节点在竞争信道时,信道的选取十分重要。Liu、Shen等[2]提出了一种针对B型LBT的主载波选择机制,即先完成LBT过程的载波被选为主载波,不观察信道情况而随意选取主信道的方式过于随意,会降低系统的性能。高通协议提出了一种基于自延迟的LBT机制来实现多载波运行。每个节点将独立执行LBT过程,如果其中一个节点完成了LBT过程,则需要继续等待,直到LBT同步边界(LSB)允许其他节点完成退避。这种方法会使得率先完成LBT过程的节点因为等待其他节点上的LBT过程而失去传输机会。Faridi A等[3]在不存在碰撞的假设下,提出了利用马尔可夫链模型来提高系统性能的方法。这种方式过于理想,在现有的无线接入机制中,不可能忽略节点之间的碰撞。Kai、Liang等[4]提出了一种实现DCB无线局域网最大吞吐量的信道分配算法。将吞吐量最大化建模为整数非线性规划问题,并采用基于分支定界法的最优信道分配算法求解该问题。这种方法计算的过程较为复杂繁琐,需要大量的计算。Lanante L等[5]提出了一种通过计算阈值来确定是否绑定更宽的信道方法,该算法需要的网络参数较多,不便收集。
近年来对深度强化学习(deep reinforcement learning,DRL)的研究十分广泛,DRL是强化学习(reinforcement learning,RL)和深度学习(deep learning,DL)的结合体,RL擅长学习解决问题的策略,但由于维度问题缺乏拓展性。DL具有强大的函数拟合能力和表示学习特性,能在一定程度上解决了自身高维度的本质特性。DRL包含了强化学习(RL)的学习能力和深度神经网络的泛化和逼近能力。在无线通信中,可以采用DRL的方式来选择最佳竞争窗口来提高系统的性能[6]。另外,流量达到的模式也可以通过DRL在线学习来适应不断变化的环境[7]。
在LAA和Wi-Fi的公平高效共存问题上,假如LAA或Wi-Fi系统其中一种使用多信道数据传输的方式,则会对另一系统不公平。目前很少有论文研究当这两类异构的网络节点同时引入多信道数据传输的技术的情况。
结合上述分析,本文提出了一种基于深度强化学习的智能算法。在将LAA的多载波LBT机制和Wi-Fi信道绑定技术同时引入信道竞争的情况下,节点通过智能信道选择来提高系统性能。另一方面,单agent DRL会使动作空间的大小随着网络异构节点的数量呈指数增长,严重影响了学习速度。为了加快学习速度,本文采用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)来快速达到收敛效果。
假设考虑有NL个LAA节点和NW个Wi-Fi节点,以及K条20MHz的基本信道。Wi-Fi节点在绑定信道时严格按照如图一所示的信道化标准[8],它可以将相邻不重叠的基本信道绑定成20 MHz、40 MHz、80 MHz、160 MHz的宽信道,且Wi-Fi节点采用802.11 ac节点。假设K=4,Wi-Fi节点i可用信道集合Ci={[1],[2],[3],[4],[1,2][3,4][1,2,3,4]}。LAA节点j在使用多载波LBT机制时,只要聚合的载波数量在候选载波数量范围之内,载波的数量以及载波是否为连续载波不受限制,因此LAA节点j可用载波(信道)集合Cj={[1],[2],[3,][4],[1,2],[1,3],[1,4],[2,3],[2,4],[3,4],[[1,2,3],[1,2,4],[2,3,4],[1,3,4],[1,2,3,4]}。在整个过程中,数据传输失败的原因只考虑到节点之间发生碰撞。另一方面,时间被离散成若干个等距时隙,即t={t1,t2,t3…tend},在每一个等距的时隙内,节点要绑定的信道参数都不会发生变化。
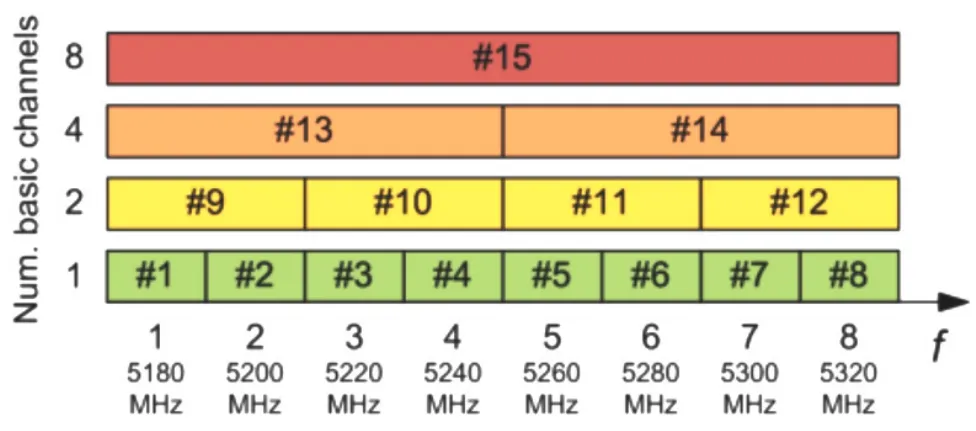
图1 802.11信道标准化
节点竞争信道的过程可以被看成典型的马尔可夫决策问题(markov decision process,MDP),该决策完全符合强化学习。强化学习是指智能体与环境进行交互的一个过程,它包含智能体、环境、动作、状态、奖励。智能体通过与环境交互,获取状态st并且经过不断地探索选择出最佳策略π。具体来讲,智能体在每一次探索中,都会执行某个动作at,此时环境会发生变化达到一种新的状态st+1,随后智能体会被给出奖励信号rt。根据这个奖励信号,智能体会按照一定的策略执行新的动作,通过不断更新策略π寻找出最大预期的Q值,如式(1)。
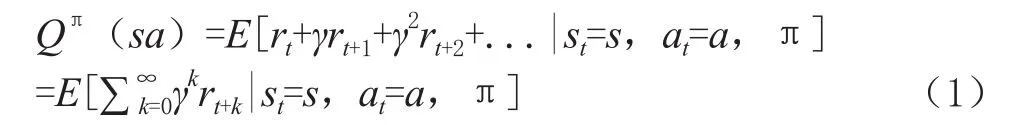
其中,Q(s,a)表示智能体在接收到当前信道的状态s后,根据策略π执行动作a,所获得的未来累计奖励。γ∈[0,1]为折扣因子。用未来的奖励乘以该因子来减弱此类奖励对智能体当前动作的影响,随后通过贝尔曼公式不断更新值函数直到逼近最优值函数,此时智能体能够学到最优的策略π*,以及对应的Q*值,如式(2)、式(3)。

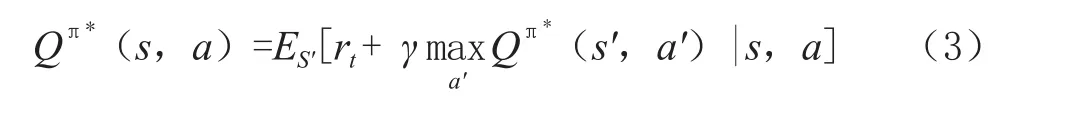
传统的RL受到维数限制,无法在大规模系统中应用,它仅仅适用于当动作空间和状态空间都比较小的场景。为了克服传统RL技术的维数限制,DRL技术被提出,它将DL集成到RL中,利用深度神经网络克服维数诅咒,从而能够有效地解决大规模问题。目前一些研究已经成功地将DRL引入到了无线应用当中[9-10]。本文针对具有连续高维状态空间和动作空间的复杂任务,进一步引入了深度确定性策略梯度(deep deterministic strategy gradient,DDPG)。DDPG属于DRL中的一种,它能够在连续的高维状态空间和动作空间中进一步完成复杂任务。该算法基于Actor-Critic架构,通过相同的神经网络框架构成当前的Actor网络和当前Critic网络,目标Actor网络以及目标Critic网络,共同来完成算法的决策和更新。当前Actor网络采用确定性策略μ来输出动作at,at=at,at=μ(st|θμ),通过目标函数J来评价策略μ,用来找到最佳策略,即μ=argmaxμ J(μ),其中θμ表示产生确定性动作的参数。当前Actor网络通过链式规则更新,如式(4)。

当前Critic网络用于拟合参数化Q函数为Q(s,a|θQ),通过均方差函数梯度更新,具体如式(5)所示,式中yi=ri+γQ′(si+1,μ′(si+1|Qμ′)|θQ′),其中μ′和Q′分别对应Actor网络和Critic网络。

目标Actor网络和目标Critic网络的更新采用软更新的形式,能够使得目标网络参数变化小,训练更易于收敛,软更新的具体形式如(6)。

本文提出了一种基于DRL的信道竞争方法。由于竞争信道的节点个数较多,动作空间的大小呈指数增长,严重影响到学习速度。为了加快学习速度,本文采用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)来较快达到收敛效果。其动作、状态、奖励设计如下:
3.1 动作
有实验和理论分析表明,信道绑定参数(P,B)对系统性能有重要影响,其中P表示主信道,B表示绑定的信道数量,为保证性能增益,应谨慎选择信道绑定参数,当基本信道K=4时,异构节点在t时刻所对应的动作空间如下。
LAA 节点i:

Wi-Fi节点j

3.2 状态
LAA节点和Wi-Fi节点采用相同的状态,定义如下:

其中ι表示为队长,λ表示数据包的到达率。
3.3 奖励
整个实验的目标是降低整个网络的实验,提高系统的吞吐量,因此奖励设计如下:

3.4 MADDPG
算法一中给出了基于MADDPG信道竞争算法的伪码,首先随机初始化Actor网络μi(s|θiμ)和Critic网络)Qi(s,a|θiQ),建立对应的Actor目标网络Q′i和Critic目标网络μ′i以及一个缓冲区。在每一个episode的最开始,节点的初始状态都为{0,0}。在时刻t,节点根据当前Actor网络选取动作,并根据动作改变信道绑定参数,获得对应的奖励以及达到的新状态,另外将全局动作、全局状态、全局奖励,和新的全局状态放入到缓冲区中。接下来的每个节点都要在缓冲尺中采样出一个尺寸大小为L的mini-batch并且通过所有节点的目标网络,缓冲区的样本以及Critic网络来计算损失,最后更新Critic网络,Actor网络以及对应的目标网络。
算法一:初始化Actor网络μi(s|θiμ)和Critic网络)Qi(s,a|θiQ),建立对应的 Actor 目标网络Q′i和 Critic目标网络μ′i以及一个缓冲区R。
a)For episode in {1,2...}do
b)初始化状态si,1= {0,0}
c)For t in {t1,t2,t3…tend}
d)For each agenti/j,选择ai/j,t=Sample [μi/j(si/j,t)]
e)根据式(8)获得奖励ri/j,t并且达到新状态si/j,t+1
f)在缓冲尺 R中存储 (st,at,rt,st+1),其中st={s1,t…sN,t},at={a1,t…aN,t},rt={r1,t…rN,t},st+1={s1,t…sN,t+1}
g)For agenti/jin {1,2,3…,N}
h)在缓冲尺R中采样出一个尺寸大小为L的minibatch
i)yi/j=ri+γQ′(si/j+1,μ′(si/j+1|Qμ′)|Qμ′)
j)根据式(3)更新actor网络
k)根据式(4)更新critic网络
l)结束
m)根据式 (6)为每一个代理更新目标网络
n)结束
4.1 仿真环境
采用Python3.6+TensFlow1.5进行模拟仿真实验。考虑到了不同节点数下的LAA和Wi-Fi竞争信道的情况,异构节点上的流量包按照随机模式到达,且在固定时间内发生变换。其主要参数如表1、表2所示。

表1 仿真参数

表2 神经网络参数
4.2 对比试验
为了证实MADDPG算法的优越性,本文将该算法的性能与如下算法进行比较。
随机选择算法(Random select):不考虑信道环境,节点完全随机选择通道键合参数。
DQN算法:该算法是每个代理独立学习并最大化其回报。对于单个agent,动作和状态的设计与MADDPG算法相同,但不是整体的平均奖励,每个agent有一个单独的奖励。
4.3 结果分析
图2显示了MADDPG算法在四种不同节点数情况下的收敛性。除波动较大的场景(c)外,其他三种场景的收敛相对稳定。这表明该算法具有良好的收敛性。图3显示了在不同场景中使用MADDPG算法时Wi-Fi和LAA各自的吞吐量,表明使用该算法时Wi-Fi和LAA的共存相对公平。图4和图5显示了四种场景下不同算法下所有节点的总吞吐量和平均延迟。结果表明,该算法的总吞吐量优于其他算法。此外,该算法的平均延迟明显低于其他两种算法。

图2 不同节点数在(a)、(b)、(c)、(d)情境下训练的总奖励


图3 不同情景下LAA和Wi-Fi各自的吞吐量

图4 不同算法下LAA和Wi-Fi节点的总吞吐量

图5 不同算法及不同总节点数下各个节点的平均时延
本文提出了一种基于MADDPG的竞争信道智能算法,在该算法中,LAA和Wi-Fi节点通过不断地探索、依据最佳策略选择出最优的主信道和信道的绑定数量来提高系统的性能,仿真结果表明MADDPG算法具有较好的收敛性,使得LAA/Wi-Fi保持相对的公平,且在吞吐量、平均时延等方面优于其他对比算法。
猜你喜欢 吞吐量载波信道 水声单载波扩频均衡技术研究舰船科学技术(2022年21期)2022-12-12历元间载波相位差分的GPS/BDS精密单点测速算法中国惯性技术学报(2020年2期)2020-07-24用于SAR与通信一体化系统的滤波器组多载波波形雷达学报(2018年5期)2018-12-05低载波比下三电平NPC逆变器同步SVPWM算法电机与控制学报(2018年9期)2018-05-142017年3月长三角地区主要港口吞吐量集装箱化(2017年4期)2017-05-172016年10月长三角地区主要港口吞吐量集装箱化(2016年11期)2017-03-292016年11月长三角地区主要港口吞吐量集装箱化(2016年12期)2017-03-20FRFT在水声信道时延频移联合估计中的应用系统工程与电子技术(2016年7期)2016-08-21基于导频的OFDM信道估计技术北京信息科技大学学报(自然科学版)(2016年5期)2016-02-272014年1月长三角地区主要港口吞吐量集装箱化(2014年2期)2014-03-15 相关热词搜索:信道,共存,算法,





