采用机器学习方法预测连续刚构桥预拱度研究
时间:2023-03-23 09:30:20 来源:千叶帆 本文已影响人
王景春,吴雨航,王大鹏,王利军,吕 盟
(1.石家庄铁道大学安全工程与应急管理学院,石家庄 050043;
2.石家庄铁道大学土木工程学院,石家庄 050043;
3.中建铁路投资建设集团有限公司,北京 100032)
连续刚构桥采用挂篮悬臂浇筑施工需经历长期复杂的过程及结构体系的转换,施工过程中温度的变化、施工荷载的不确定性、预应力张拉误差及混凝土收缩徐变等因素均对成桥结构变形产生很大影响[1-3]。若立模高程设置不合理,很可能会导致桥梁预拱度设置过小或合龙时合龙段两端高差较大等状况[4-5]。为保障桥梁能够顺利合龙,确保施工完成后桥梁线形符合设计要求,需根据已完成梁段的预拱度,计算相应的调整参数,控制待施工梁段的施工过程。
当前,桥梁预拱度的预测一般采用灰色理论、卡尔曼滤波和最小二乘法等[6-8],这些方法存在计算量较大且只能处理线性关系等缺点。随着工业4.0的推进,智能算法的发展给桥梁施工线形控制带来了新的动力,基于数据驱动的机器学习方法逐渐被应用到桥梁线形控制领域。习会峰等[9]建立了立模高程和影响因素之间的BP神经网络模型,可为类似桥梁计算分析提供参考;
WANG等[10]使用改进的贝叶斯动态线性模型对大跨度桥梁温度引起的应变进行建模和预测;
WANG等[11]利用思维进化算法优化的BP神经网络模型对连续刚构桥挠度进行预测。周双喜等[12]利用思维进化算法优化极限学习机对大跨度连续刚构施工立模高程进行了预测,其预测精度高,研究成果对桥梁线形控制有较大实用价值。
以上研究成果表明,机器学习算法能够有效地与桥梁施工控制领域进行交叉,且研究结果对工程实际问题有较高的参考价值。然而,以上研究均只采用单个机器学习算法对桥梁线形进行预测,未将桥梁边跨和中跨预拱度分开计算分析。实际上,不同的机器学习算法所擅长解决的问题各不相同。基于此,本文拟利用机器学习算法强大的非线性映射拟合及预测能力,分别采用梯度提升回归、极端梯度提升、支持向量机回归模型、随机森林回归模型、决策树模型等5种典型的机器学习方法实现连续刚构桥边跨和中跨预拱度预测,并根据评价结果进行模型比选。与现有研究相比,本文在选择影响预拱度的因素方面更为全面,共选择9了个影响因素。其次,分别构建桥梁边跨和中跨数据集,根据边跨和中跨数据特征,分开对数据集进行训练,选择适用于边跨和中跨预拱度预测的机器学习算法。采用训练好的模型对项目桥梁预拱度进行预测,相关研究可为连续刚构桥悬臂浇筑施工提供参考和借鉴。
1.1 数据收集
收集阳泉市绕城改线工程中土木垴大桥、南石大桥、庄窝大桥及西郊大桥4座大桥共196组预拱度数据,其中,西郊大桥的40组数据用于模型检验,其余数据用于模型训练。所涉及的影响因素主要有悬臂长度L、梁段质量M、梁高H、腹板厚度F、底板厚度D、温度T、混凝土容重γ、弹性模量E、强度P。表1列出了4座大桥的宏观参数。由于篇幅限制,表2仅列出了土木垴大桥左幅3号墩中跨部分样本数据。

表1 桥梁宏观参数
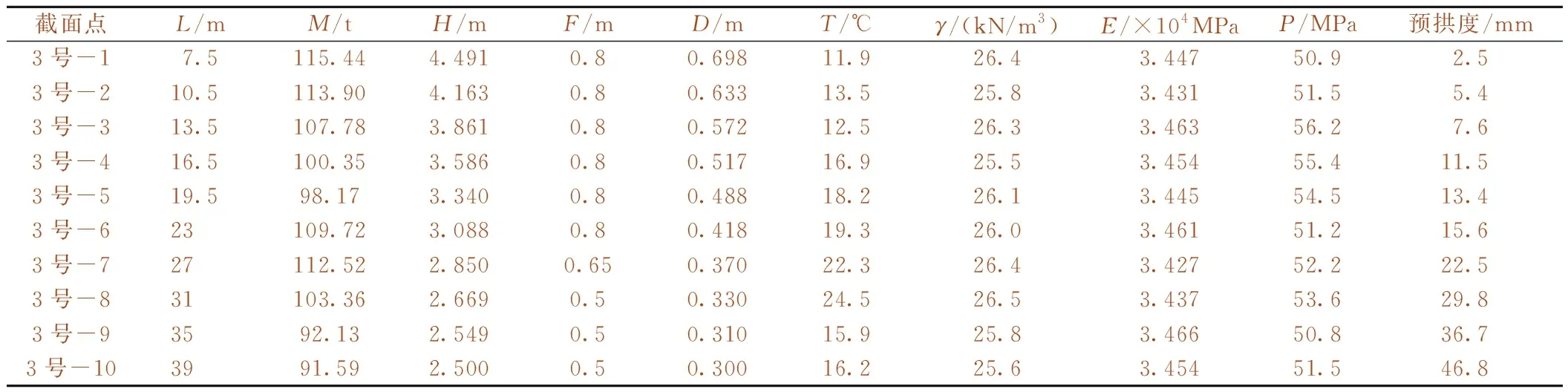
表2 左幅3号墩中跨部分样本数据
1.2 数据预处理
测量数据中含有部分奇异样本,因这类样本实测数据存在较大的偶然误差,通常会被剔除。为尽可能多地保留样本,对剔除的混凝土容重和强度进行了缺失值填充,填充时尽可能不改变数据的分布特征。通过对比采用完整数据的众数、中位数、分位数、均值等填充方法的效果,获得使模型准确率最高时的空值填充方法,即同一类别所有完整样本混凝土容重和强度的均值。
由于输入变量存在数量级差异,训练过程中预测精度和训练速度会有所降低,采用z-score方法[13]对收集的数据进行归一化,消除不同变量间的量级差异。归一化公式如下
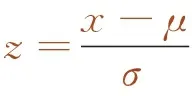
(1)
式中,μ为样本均值;
σ为样本标准差。
训练模型之前,将土木垴大桥、南石大桥、庄窝大桥边跨数据和中跨数据按7∶3随机划分为训练集和测试集,因此,边跨和中跨训练集和测试集样本数均为54和24。应用训练好的模型对西郊大桥边跨和中跨40组数据进行预拱度预测。
2.1 梯度提升回归
梯度提升回归(Gradient Boosting Regression,GBR)是一种集成学习算法[14]。该算法通过优化可微分损失函数来构建一系列弱模型,算法训练当前基学习器的重点是学习前一个基学习器的误差,训练过程中,以负梯度作为评估指标来衡量前一个基学习器的误差,在接下来的学习中,之前的误差会通过拟合负梯度来更新。使用GBR算法通常不需要进行复杂的数据处理过程并且准确性较高。具有M个树的GBR可以表示为

(2)
式中,hm为单独表现较差的弱学习器;
γm为添加一棵树对模型贡献的比例因子。GBR使用梯度下降损失函数,通过使用新的估计更新初始估计来最小化误差。
2.2 极端梯度提升
极端梯度提升(Extreme Gradient Boosting,XGBoost)是陈天奇提出的一种提升方法,属于boosting类型[15]。该算法采用CART作为基分类器,由多个相关决策树共同决策,算法在损失函数中加入了正则项,并通过二阶泰勒对损失函数展开,有效提高了计算精度,避免算法过拟合,此外XGBoost算法能够进行分布式计算,拟合精度比同类提升树算法的更高。其计算式为
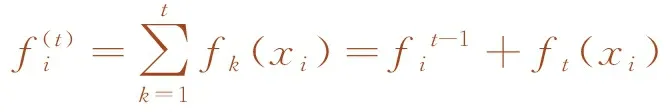
(3)
2.3 支持向量机回归
支持向量机回归(Support Vactor Regression,SVR)也称ε-SVR,是基于支持向量机(Support Vector Machine, SVM)进行回归分析的机器学习算法[16]。基本目标是在SVR模型中准确拟合回归函数y=f(x),从而根据给定的训练数据准确预测一组输入样本{xi}对应的目标{yi}。对于非线性问题,通过引用核函数(Kernel)扩展特征空间,将低维非线性问题转化为高维线性问题。本文核函数选取高斯径向基函数[17]

(4)
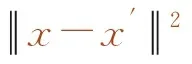
2.4 随机森林
随机森林(Random forest,RF)是一种具有随机子空间和随机分裂选择特性的集成算法。该算法采用bootstrap采样技术,从原始数据集中提取多个不同的训练数据集并放回数据,然后结合随机子空间方法对每个bootstrap数据集进行决策树建模[18-19]。通过对大量决策树的分析,得出最终预测结果。对于回归算法,预测结果为所有决策树输出结果的平均值

(5)

2.5 决策树
决策树(Decision Tree,DT)的基本思想是通过进行一系列简单的测试,对数据进行分区并在每个分区内拟合预测模型[20]。一颗决策树包含1个根节点、若干内部节点和叶节点。其中,决策树的叶节点对应决策结果,决策树的其他节点对应一个属性测试,根据属性测试结果将样本划分至下一子节点中,通过不断重复属性测试操作,最终,所有的样本都会被划分至叶节点,即决策结果。
使用平均绝对误差(MAE)、均方根误差(RMSE)和确定性系数(R2)对5种算法的预测性能进行评估和对比[21],具体表达式如式(6)~式(8)所示。
(6)

(7)

(8)

4.1 模型预测效果
基于Python语言,在Jupyter notebook平台实现了以上5种机器学习算法并对西郊大桥进行结果测试。考虑到收集的数据样本量较小,且期望能够最大化地利用数据样本,训练过程中采用了K-10折交叉验证方法。图1给出了不同机器学习算法在边跨和中跨数据集上的平均绝对误差和均方根误差。图2和图3给出了不同机器学习算法在边跨和中跨数据集预测的确定性系数。
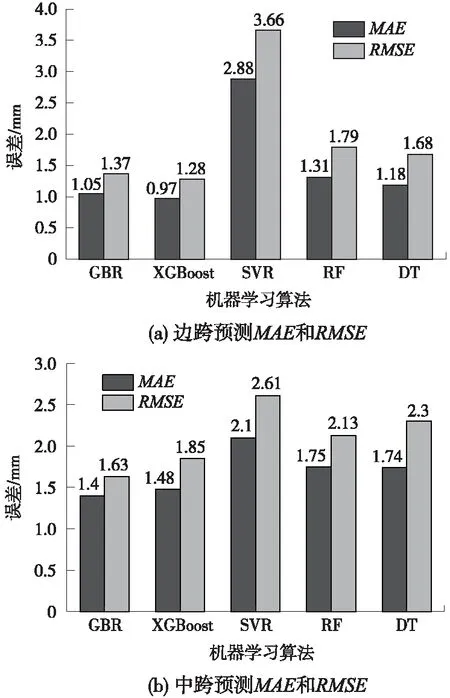
图1 不同机器学习算法MAE和RMSE
由图1(a)可知,XGBoost算法在边跨测试集上MAE和RMSE值最低,分别为0.97 mm和1.28 mm,而SVR模型性能较差,MAE和RMSE值较高,分别为2.88 mm和3.66 mm。由图2可知,XGBoost算法在边跨训练集和测试集上R2最为接近1,分别为0.998和0.944,SVR模型在边跨训练集和测试集上R2分别为0.849和0.747。据此,XGBoost算法在边跨预拱度预测表现最好。综合图1(a)和图2可知,不同机器学习算法在边跨数据集上性能表现次序为:XGBoost>GBR>DT>RF>SVR。
由图1(b)可知,GBR算法在中跨测试集上MAE和RMSE值最低,分别为1.4 mm和1.63 mm,而SVR模型性能较差,MAE和RMSE值较高,分别为2.1 mm和2.61 mm。由图3可知,GBR算法在中跨训练集和测试集上R2最为接近1,分别为0.995和0.989,SVR模型在中跨训练集和测试集上R2分别为0.771和0.781。据此,GBR算法在中跨预拱度预测表现最好。综合图1(b)和图3可知,不同机器学习算法在中跨数据集上性能表现次序为:GBR>XGBoost>RF>DT>SVR。
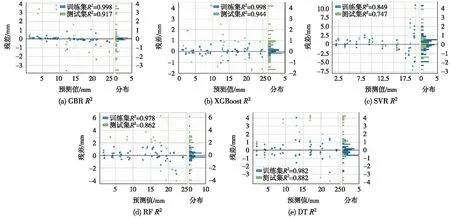
图2 边跨R2

图3 中跨R2
任何预测方法均有其适用性和局限性,不存在一种适用于所有预测的通用方法,应依据实际问题选择适当的方法。本次采用的5种机器学习方法,较好地实现了对连续刚构桥拱度的预测。模型泛化能力较好,能够将学习成果应用于新的数据集。
4.2 实例分析
应用训练好的机器学习模型对西郊大桥15号墩和16号墩悬臂浇筑阶段预拱度进行预测,T构分段如图4所示。边跨和中跨各悬臂段预测误差如图5所示。由图5(a)知,XGBoost算法在边跨预测最大误差为3.9 mm,DT、GBR、RF及SVR四种算法预测最大误差分别为5.2,6.3,8.1 mm及8.6 mm,XGBoost算法在边跨预测误差较小。由图5(b)知,GBR算法在中跨预测中性能最优,最大误差不超过3.5 mm,DT、XGBoost、RF及SVR预测最大误差分别为8.4,4.3,4.7 mm及5 mm。总的来说,以上5种机器学习算法预测误差趋势基本相同,对西郊大桥的预测结果均表现良好,尤其是XGBoost算法和GBR算法。

图4 15号墩和16号墩T构分段(单位:cm)

图5 西郊大桥5种预测模型预测误差对比
本文基于5种机器学习算法(GBR、XGBoost、SVR、RF、DT),提出了快速预测连续刚构桥预拱度的智能化策略。
(1)考虑悬臂长度、梁段质量、梁高等9项桥梁设计参数作为机器学习算法的输入向量,全面反映影响桥梁预拱度的因素。
(2)使用5种机器学习算法对数据集进行训练,通过对比5种机器学习算法性能可知,XGBoost算法在边跨数据集上MAE和RMSE较小,R2最接近1,模型性能表现最好。GBR算法在中跨数据集上性能表现最好。模型泛化性能好,可用于连续刚构桥预拱度预测。
(3)将训练好的模型用于待施工梁段的预拱度预测。预测结果与实际值误差较小,模型预测精度较高,能够在不进行桥梁结构仿真分析的前提下,快速给定边跨和中跨各悬浇段预拱度。研究成果为桥梁施工智能化提供了思路。
机器学习作为数据驱动的预测方法,数据量是提高算法精度的关键。另外,机器学习方法属于“黑箱模型”,其特征选取较为依赖先验知识,这在将机器学习算法应用到桥梁线形预测领域时需要格外注意。本文收集的数据为同一项目不同标段内桥梁,桥梁跨度相差不大,预测精度较高。未来若能进一步拓展数据集,收集跨度相差较大的桥梁,对预测跨度较大的桥梁亦能取得较高精度。
猜你喜欢 预拱度集上机器 机器狗环球时报(2022-07-13)2022-07-13机器狗环球时报(2022-03-14)2022-03-14高墩大跨连续刚构桥预拱度仿真分析四川建材(2020年7期)2020-07-26Cookie-Cutter集上的Gibbs测度数学年刊A辑(中文版)(2020年2期)2020-07-25链完备偏序集上广义向量均衡问题解映射的保序性数学物理学报(2019年6期)2020-01-13分形集上的Ostrowski型不等式和Ostrowski-Grüss型不等式井冈山大学学报(自然科学版)(2019年4期)2019-09-09高速铁路混凝土梁式桥预拱度设置的探讨铁道建筑(2019年6期)2019-07-25跨度128 m高速铁路系杆拱桥拱肋拟合预拱度研究铁道建筑(2018年10期)2018-11-01未来机器城电影(2018年8期)2018-09-21浅谈钢箱桥预拱度的设置科技视界(2014年7期)2014-12-24 相关热词搜索:学习方法,采用,机器,





