萤火虫算法优化支持向量机室内定位研究*
时间:2023-02-24 20:10:05 来源:千叶帆 本文已影响人
仲 臣,余学祥,邰晓曼,韩雨辰,肖星星,刘清华
(1.安徽理工大学空间信息与测绘工程学院,安徽 淮南 232001;
2.安徽理工大学矿山采动灾害空天地协同监测与预警安徽普通高校重点实验室,安徽 淮南 232001;
3.安徽理工大学矿区环境与灾害协同监测煤炭行业工程研究中心,安徽 淮南 232001)
随着无线信息及智能终端的快速发展,基于位置服务的需求量日益增长。目前,室外定位技术已趋于成熟,其精度可达亚米级。相比之下,室内定位技术由于全球导航卫星系统GNSS(Global Navigation Satellite System)定位信号难以穿透墙体,同时受室内环境条件限制难以获取高精度定位。
近年来,基于室内信号介质的WiFi技术、蓝牙技术、射频识别技术、超宽带技术、红外线定位技术和地磁定位技术等被广泛研究。其中,WiFi定位技术能较好地满足日常生活所需,但WiFi信号强度具有多变性,且信号接入点存在冗余信息,使基于WiFi的室内定位面临挑战。针对上述问题,一些学者利用数理统计理论,将机器学习算法与其结合,提升了定位精度。文献[1]引入K邻近KNN(K-Nearest Neighbor)算法,利用指纹存在的时序特征差异性对WiFi指纹信息进行基准坐标选择,并修正其输出结果附加权值,获得了较为稳定的定位结果。文献[2]提出了一种高斯径向基核函数加权的KNN算法,并对无线信道状态信息进行滤波处理,使定位精度进一步提升。文献[3]利用卷积神经网络模型结合WiFi指纹库,提升了定位精度的同时缩短了定位所需时间。文献[4]提出利用人工鱼群算法对BP神经网络进行优化,将神经网络的初始权值与阈值作为种群的寻优目标,以此建立位置坐标与信号强度之间的对应关系,提升了定位可靠性。文献[5]基于信号结构的多样性建立无线电室内地图,并将其2种不同频率合成至指纹数据集中,进一步优化了定位精度。文献[6]基于KNN算法,将空间距离参数进行优化,在低成本硬件设施的基础上提高了WiFi的定位精度及稳定性。
由以上研究成果可知,KNN、神经网络均可与WiFi定位融合达到实际应用要求的精度。但是,当室内定位范围较大时,样本数量较多,采用KNN算法空间复杂性高,易出现分布不均匀的情况,且对K值的选择过于敏感,导致计算量增大[7]。同样神经网络对样本点有严格的要求,易出现过拟合情况,从而限制其应用范围。相比以上2种算法,支持向量机SVM(Support Vector Machine)具有一定的普适性,能很好地简化空间复杂性,且存在更好的泛化推广性。研究表明,核函数的选取对支持向量机的优劣有着决定性作用,在室内定位中,函数参数选择不当会导致定位精度较低。
针对核函数参数的选取问题,本文提出一种基于萤火虫算法FA(Firefly Algorithm)优化的支持向量机室内定位算法。萤火虫算法的原理与实现均较为简单,无需调整过多参数,能较好地改善SVM的回归过程,从而进一步提升定位效果[8]。
2.1 支持向量机
对于给定的某一样本集{mi,ni},i=1,2…,N,mi∈Rd,ni∈{+1,-1},利用超平面将样本集中不同类别的样本区分开,该超平面可表示为式(1):
ωT·m+b=0
(1)
其中,ω=(ω1,ω2,ω3,…,ωd)为法向量,m为样本向量,b为原点至超平面的位移。同时,若该超平面能将所有样本正确分类,应满足式(2),最优分类超平面如图1所示。图1中,F1,F2,F3分别代表分类函数,分别位于F1和F3上的正样本(+)和负样本(-)即为支持向量。
(2)
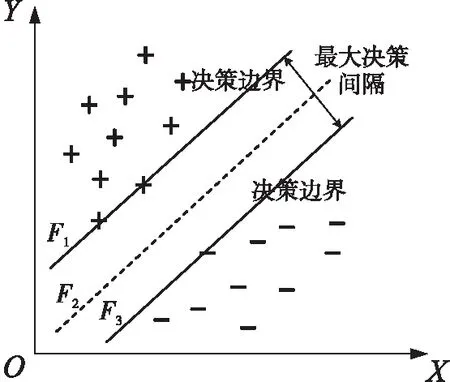
Figure 1 Classification hyperplane图1 分类超平面
分类完成后,最大化决策间隔可使分类效果达到最优,其间隔表达式如式(3)所示:
s.t.ni(ωTmi+b)≥1,i=1,2,…,N
(3)
式(3)即为SVM基本型,同时依据超平面的函数模型,结合凸二次规划的优化解法,将拉格朗日乘子引入式(3)中并构造如式(4)所示的函数:
(4)
其中,拉格朗日乘子δi(i=1,2,…,N)为标量,可将约束条件函数与原函数联系起来;
N为样本向量m的个数。决策函数如式(5)所示:
(5)

通常核函数的选取标准不唯一,根据实际问题来确定。二维高斯函数具有旋转对称性,且可分离性较好,因此本文选择高斯径向基核函数,则式(5)变换为式(6):
(6)
其中,C为惩罚因子,σ为径向基核函数的参数。
2.2 萤火虫算法
萤火虫算法的灵感源自萤火虫群体的信息交换行为,萤火虫之间通过光亮进行相互吸引。该算法原理较为简单、性能稳定且全局和局部寻优能力强,能得到令人满意的优化精度,被广泛应用于各种优化问题,在WiFi指纹定位中能更好地建立信号与平面坐标之间的非线性关系。
为方便起见,假设萤火虫之间的吸引度与其亮度成正比。为了降低算法的复杂度,设第v只萤火虫所处的位置向量为xv=(xv1,xv2,xv3,…,xvn),n为位置向量维度,位置向量的目标函数值与其绝对亮度Iv相等,即Iv=f(xv);
再设存在另外一只萤火虫j的亮度值更大,即Ij>Iv,Ij=f(xj);
此时,该萤火虫存在吸引力使亮度较小的萤火虫聚集。若上述2只萤火虫的距离为dvj,相对亮度为Ivj(dvj),考虑到距离变化及空气吸收对光亮的影响,可得式(7):
(7)
(8)
其中,ρ为空气对光的吸收系数,一般取[0.01,100]的任意常数。
设萤火虫v、j之间的吸引力与相对亮度Ivj(dvj)成一一映射关系,可定义吸引力αvj(dvj)如式(9)所示:
(9)
其中,α0为光源处对萤火虫的吸引力,即最大吸引力,取值为1,同时吸引过程中亮度较小的萤火虫v会随时刻变化不断更新自身位置,如式(10)所示:
xv(t+1)=xj(t)+αvj(dvj)(xv(t))+βλj
(10)
其中,xv和xj分别为2只萤火虫所处的位置向量,t为迭代次数,β为[0,1]的常数,λj为随机向量。
2.3 萤火虫算法优化的支持向量机算法
本文针对SVM模型中的2个主要参数C和σ,引入萤火虫算法对其进行优化,提出FA-SVM算法并应用于WiFi室内定位,其步骤如下所示:
(1)采集实验所需数据,并将其划分为学习与测试2种不同的类别。
(2)设定SVM模型中的2个主要参数C和σ的取值范围,以此确定萤火虫种群大小,并初始化种群个体的位置与亮度。
(3)进入循环。通过计算获得萤火虫个体间的吸引力αvj(dvj)与其相对亮度Ivj(dvj),并更新萤火虫种群的个体位置和适应度值。
(4)根据SVM参数优化的数学模型及最优定位精度更新萤火虫个体的适应度值。
(5)判定是否满足终止条件。若不满足,返回步骤(3),若寻得最优参数解,则输出结果。
(6)将该参数结果应用于室内定位中,并进行数据预测。
FA-SVM算法流程图如图2所示。

Figure 2 Flow chart of FA-SVM algorithm图2 FA-SVM算法流程图
在室内定位离线阶段,对于从定位区域采集的信号强度值RSSI(Received Signal Strength Indication),通过奇异谱分析进行预处理,去除信号噪声,以提高数据质量,保证定位精度及结果的稳定性[9]。将预处理后的数据分为训练样本和测试样本,计算适应度值次数作为迭代次数,达到最大迭代次数即满足终止条件,通过萤火虫算法寻求最优参数(C,σ),训练数据并建立对应的室内定位回归模型,对测试样本进行预测,分析定位误差,判断模型的可靠性及稳定性。定位研究在线阶段以用户采集的实时RSSI数据作为输入,通过离线阶段建立的室内定位回归模型输出预测的位置坐标[10]。
3.1 奇异谱分析
由于室内定位存在不确定因素,采集的数据易受到干扰,RSSI值存在信号波动,为了获得相对稳定的数据,本文采用奇异谱滤波算法对数据进行预处理。奇异谱分析主要包括4个步骤:嵌入、分解、分组和重构。
输入序列长度为M的数据集X={x1,x2,x3,…,xM},选择合适的窗口长度L(通常取L<2/M),确定K=M-L+1(即K>L),将输入的原始序列映射为L×K的轨迹矩阵,则嵌入的轨迹矩阵X如式(11)所示:
(11)

(12)
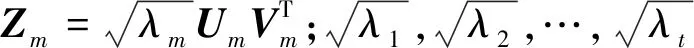
接着进行分组,对矩阵的奇异值进行降序排序,一般取前几个较大的奇异值反映数据的特征,其余部分作为噪声去除。
最后采用对角平均化的方式,将轨迹奇异分解的矩阵转化为长度为M的序列,将L行K列的矩阵P作为分组后的矩阵,p为矩阵P中的元素。则重构序列rk如式(13)所示:
(13)
通过式(13)获得去噪后的数据,信号强度滤波后如图3所示,结果表明奇异谱滤波去除了噪声,提高了数据的准确度。

Figure 3 Signal strength filtering图3 信号强度滤波
为验证信号滤波后可以提高定位精度,本文选取滤波处理后的数据和未经滤波处理后的数据进行待测点预测,误差对比如图4所示,具体数值如表1所示。对比室内定位精度发现,3 m以下定位误差占比明显增多,滤波处理后的数据较未滤波处理的数据平均定位误差提高了18%。实验说明滤波处理后的数据具有更高的准确度且保留了原始信号的特征。
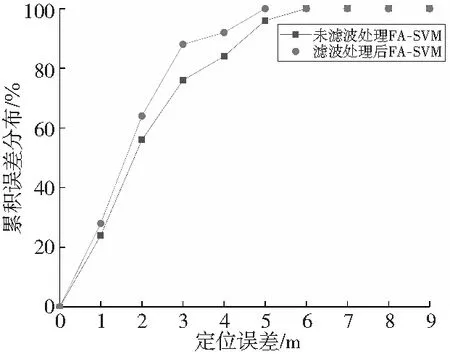
Figure 4 Comparison of positioning accuracy before and after filtering图4 滤波前后定位精度对比
3.2 基于FA-SVM分类和回归的室内定位
假设选取长为l、宽为w的教室作为实验区域并将其划分为1 m×1 m组成的格网进行数据采集。

Table 1 Comparison of filtering performance
笔记本电脑作为信号接收器,在每个网格节点处进行数据采集,实测数据为h个接入点AP(Access Point)的RSSI组成的向量。
室内定位离线阶段对实测数据进行奇异谱滤波预处理,将实测数据中的80%作为训练数据,其余20%作为测试数据,以(RSSI1,RSSI2,RSSI3,RSSI4,x,y)数据格式输入SVM模型中,设置SVM参数区间为C(0,100],σ(0,1000],FA-SVM算法中适应度函数f(x)的计算公式如式(14)所示:
(14)
其中,Q为数据库样本点数;
x′q和y′q分别为第q(q∈[1,Q])个样本预测定位点坐标;
xq和yq分别为第q个样本实际坐标。
经过100次迭代寻优,求得最佳参数(C,σ),用于SVM室内定位模型预测未知点。在线阶段利用实时RSSI值计算位置坐标。
4.1 实验环境
本文选取安徽理工大学空间信息与测绘工程学院一楼作为实验区域,实验区域长20 m,宽30 m,涵盖球场、厕所、走廊及实验室,具体情况如图5所示;
选取4个相同的小米路由器作为接入点,布置在房间拐角处,信号覆盖整个实验区域。除墙体外,将实验区域划分为2 m*2 m的网格,于网格节点处采集RSSI值,共有145个节点,每个节点处采集50次。通过奇异谱滤波预处理RSSI数值,将处理后的数据的80%用于训练,其余20%用于测试,把训练集输入支持向量机中,利用萤火虫算法寻找最优惩罚参数C和属性系数σ,建立室内定位回归模型,并且采用5折交叉验证,确保模型的精度。

Figure 5 Experimental area图5 实验区域
4.2 结果与分析
本文选取萤火虫算法和粒子群优化PSO(Particle Swarm Optimization)算法对SVM参数优化进行对比,并选用KNN算法和加权K-最近邻WKNN(Weighted K-Nearest Neighbor)算法对比验证FA-SVM算法用于大范围室内定位具有更明显的定位优势,证明萤火虫算法寻优的SVM回归模型提高了定位精度和稳定性,可将定位误差控制在实际应用的范围内。
4.2.1 SVM参数寻优
FA-SVM和PSO-SVM参数寻优曲线如图6所示,具体数值如表2所示。相对于PSO-SVM算法,本文提出的FA-SVM算法收敛速度更快、寻优效率更高,可在较短时间内寻找到最优参数向量。

Figure 6 Optimization convergence curves图6 寻优收敛曲线

Table 2 SVM parameters
4.2.2 定位精度
前文数据预处理部分的实验表明了滤波前后定位误差存在差异,为控制单一变量,以下实验均使用奇异谱滤波处理后的数据进行待测点预测。FA-SVM、PSO-SVM、WKNN和KNN 4种定位算法的定位结果如图7所示,定位结果统计如图8所示,定位累计误差分布如图9所示。

Figure 7 Comparison of positioning results图7 定位结果对比

Figure 8 Positioning result statistics图8 定位结果统计

Figure 9 Distribution of cumulative positioning errors图9 定位累计误差分布图
分析图表可得,FA-SVM算法定位误差在5 m以内,且2 m以内误差占比过半;而PSO-SVM算法定位误差仍集中在3 m左右,部分误差在6 m以上。说明萤火虫算法优化的SVM参数优于粒子群优化算法,不易受到数据噪声的影响,鲁棒性好,能更好地刻画RSSI值与平面坐标xy的非线性关系。同时,观察FA-SVM算法、WKNN和KNN算法发现,WKNN和KNN算法定位误差波动大,存在10 m以上误差,严重影响室内定位实用性和稳定性,表明本文算法鲁棒性更好。
4种算法定位误差对比如表3所示。比较表3的最大定位误差、最小定位误差和平均定位误差可知,FA-SVM平均定位误差较PSO-SVM算法降低了17.7%,最小定位误差较PSO-SVM算法降低了23.8%,最大定位误差较PSO-SVM算法降低了19.3%。说明萤火虫算法寻找的最优参数存在更高的稳定性,可提高室内定位的定位精度。观察WKNN和KNN算法可知,大部分点定位于8 m以下,且存在10 m以上误差,定位过程中可能随时偏移实际位置,影响室内定位效果。

Table 3 Performance comparison of four algorithms
选取部分实验点进行室内定位坐标点对比,如图10所示。FA-SVM算法待测点预测坐标更加贴合实际坐标,PSO-SVM算法待测点预测坐标几乎偏离实际位置,对比可得,FA-SVM算法定位待测点具有更高的稳定性和更高的定位精度。

Figure 10 Comparison of positioning coordinates图10 定位坐标对比图
4.2.3 定位速度
FA-SVM和PSO-SVM的定位耗时如图11所示。通过2种寻优算法建立的室内定位回归模型进行定位,可发现随着训练集中样本数量增加,未知点定位耗时不断增加,但是,FA-SVM定位耗时一直低于PSO-SVM,总体趋势几乎没有变化。说明FA-SVM算法简单,定位速度更快,定位耗时不易受样本数量大小的影响,在数据库样本数量较大时,提高了室内定位的时效性,满足了室内实时定位的要求,应用前景更广。

Figure 11 Comparison of positioning speed图11 定位速度对比
针对KNN、神经网络等机器学习在室内定位应用中存在的不足,本文提出了一种基于萤火虫算法优化支持向量机的室内定位算法。室内定位离线阶段,将奇异谱滤波后的数据输入支持向量机中,并用萤火虫算法寻求支持向量机最优参数,建立室内定位回归模型。实验结果表明,FA-SVM算法不仅收敛速度快、寻优效率高且不易受环境影响,提高了室内定位的精度及鲁棒性,能较好地应用于实际生活中。
猜你喜欢 定位精度萤火虫滤波 船岸通信技术下舰船导航信号非线性滤波舰船科学技术(2022年20期)2022-11-28北方海区北斗地基增强系统基站自定位精度研究导航定位学报(2022年5期)2022-10-13Galileo中断服务前后SPP的精度对比分析导航定位学报(2021年4期)2021-08-29一种考虑GPS信号中断的导航滤波算法北京航空航天大学学报(2019年9期)2019-10-26GPS定位精度研究智富时代(2019年4期)2019-06-01GPS定位精度研究智富时代(2019年4期)2019-06-01高效LCL滤波电路的分析与设计电子制作(2019年9期)2019-05-30基于EKF滤波的UWB无人机室内定位研究电子制作(2018年16期)2018-09-26萤火虫小天使·一年级语数英综合(2018年7期)2018-09-12萤火虫小天使·一年级语数英综合(2017年6期)2017-06-07 相关热词搜索:向量,萤火虫,算法,





