融合多特征的专利功效短语识别
时间:2023-03-03 15:55:04 来源:千叶帆 本文已影响人
罗艺雄,吕学强,游新冬
(北京信息科技大学 网络文化与数字传播重点实验室,北京 100101)
专利作为先进技术的最通用载体,其规模仍在逐年增长。中国国家知识产权公布的数据显示[1],2020年1月至8月,我国发明专利申请95.2万件,发明专利授权31.1万件;
实用新型专利申请182.8万件,实用新型专利授权 149.6万件。面对大规模的专利数据,专利分析者需要借助分析技术和管理工具对其进行科学的研究挖掘。在各种分析技术和管理工具中,专利技术功效图具有简洁明了、通俗易懂的特点,但由于人工构建的模式制作成本高、研发周期长,从而没有被大规模地推广使用[2]。如何借助计算机提高技术功效图构建的自动化程度,已成为智能构建技术功效图的研究重点。技术功效图的构建可以分为三部分:
技术主题识别、功效短语识别、技术功效矩阵构建,其中技术主题识别和功效短语识别是构建技术功效图的基础。因此,技术主题识别和功效短语识别的自动化程度和精度的进步能够提高技术功效图的构建效率和质量。
1.1 技术短语和功效短语抽取
根据技术短语和功效短语两者的识别顺序,可以分为异步模式和同步模式。其中,异步模式中对技术短语和功效短语分别采用不同的策略独立识别。陈颖等[3]基于德温特专利数据库,结合专利摘要结构、词性和线索词三类特征制定抽取规则,实现候选技术功效词的自动抽取,减少了构建技术功效图的人力成本。张博培等[4]观察分词结果发现功效词可能被切分成多个词,所以先根据词性将被切分开的两个词合并为一个词,然后使用隐马尔可夫模型实现对单词功效词和双词功效词的识别。胡菊香等[5]先通过线索词定位到可能包含技术功效的句子,再基于词的共现频率提取出功效短语的构词规则,而后使用规则功效识别短语。Trappey等[6]先结合本体人工定义技术主题和功效主题,进一步结合领域文本中单词统计特征挖掘出各主题下高频的技术短语和功效短语,最后使用专利文本中提取的关键词和每个主题下的技术短语或功效短语集合计算相似度,确定专利的技术主题和功效主题。马建红等[7]针对复合功效词识别困难的问题,先使用规则合并候选复合功效词,然后使用条件随机场(Conditional Random Field,CRF)对候选短语分类得到复合功效词。异步模式中,技术功效词的识别主要通过规则和传统机器学习模型实现,但是面对多变的文本格式,人工定义的规则往往不具有完备性,识别结果的查全率较低,而传统机器学习方法存在查准率较低的问题。
在同步识别模式中,技术短语和功效短语作为SAO(Subject-Action-Object)结构的组成部分同时被识别。段庆峰等[8]采用斯坦福大学开源的软件Open IE实现SAO三元组的抽取,进一步结合触发词和专家意见识别出技术短语和功效短语,最后通过聚类分析得到技术主题和功效主题。翟东升等[9]将德温特专利数据库中专利摘要的新颖性和优势字段作为语料,使用自然语言处理(Nature Language Process,NLP)工具包Spacy抽取SAO结构,而后由专家将SAO结构标注为技术问题、技术方案、技术功能、技术效果4种语义类型。同步模式依赖于NLP工具和专家意见,不遵循SAO结构的技术短语和功效短语会被遗漏,从而导致查全率低。
综上所述,基于规则和基于SAO结构的识别方法无法覆盖专利文本中所有的功效短语,而基于传统机器学习方法的功效短语识别精度不足。为了提升专利功效短语的抽取效果,本文将功效短语识别任务转换为命名实体识别 (Named Entity Recognition,NER)。目前,神经网络方法已经在命名实体识别任务上取得了优异的效果。因此,本文采用融合多特征的神经网络方法实现专利功效短语的抽取。
1.2 命名实体识别
命名实体识别是自然语言处理中的基础任务,目标是从文本中抽取出对应特定实体类型的短语,抽取出的实体短语可以辅助实现更复杂的NLP任务。
Ma等[10]对构成英文单词的字母序列向量化后,使用卷积神经网络编码得到单词的字符级别特征向量,然后与单词向量拼接后输入到组合了双向长短时记忆网络(Bi-directional Long-short Memory,BiLSTM)和CRF的模型中预测命名实体。李丽双等[11]针对不同类别的字符(大写字母、小写字母、标点、数字等)分别初始化为不同的向量,进一步使用CNN抽取字符特征嵌入并拼接对应的单词嵌入后,输入到BiLSTM+CRF中抽取生物医学实体。殷章志等[12]使用BiLSTM+CRF基于字符和基于单词分别训练NER模型,进一步通过拼接单词NER模型中BiLSTM的输出和对应组成单词的各个字符在字符NER模型中BiLSTM的输出得到分值向量,最后将分值向量输入到支持向量机中训练,实现了对字词NER模型的融合。陈茹等[13]通过注意力机制融合单词、字符和部首等信息丰富的单词嵌入,进一步对单词嵌入使用空洞卷积编码得到单词的特征向量,然后使用自注意力机制得到融合单词上下文的特征向量,最后使用CRF预测单词的NER标签。
综上所述,深度学习模型在NER任务中被广泛使用,且融合字符和单词信息可有效提升NER性能。本文在模型嵌入层引入了汉字字符的拼音和五笔特征,并利用注意力机制得到字符的单词级特征向量,最后融合多特征的向量作为BiLSTM+CRF模型的输入,在新能源汽车专利数据集上训练和测试。本文在新能源汽车专利数据集上的功效短语识别F1值达到91.15%,抽取效果优于目前的方法。
在目前的中文专利功效短语抽取方法中,处理的最小单元普遍为单词,所以必须对语料进行分词。然而,分词操作会将部分功效短语划分为多个单词,导致现有方法在识别前需要考虑单词合并的问题。另外,在之前的研究中没有考虑到分词带来的另一问题:
分词错误可能导致功效短语边界被错误分割,进而使得功效短语不能被识别。例如,对“具备高阻燃性能。”使用自然语言处理工具LTP(1)https://pypi.org/project/pyltp/分词,得到的结果为“具备/高阻/燃/性能/。”,“阻”被划分到了单词“高阻”中,从而导致功效短语“阻燃性能”无法被识别。
为了避免中文的分词操作对功效短语识别的影响,本文使用字符作为输入序列的最小单元,并在模型嵌入层融合字符级特征和单词级特征增强识别的效果,功效短语识别模型结构如图1所示。

图1 融合多特征的专利功效短语识别模型结构图
2.1 嵌入层
模型在嵌入层通过Word2Vec或预训练模型BERT[14]将各特征转化为固定维数的稠密向量,再使用拼接的方式融合不同的特征组合得到最终输入编码层的向量。
2.1.1 字符特征
基于字符输入的模型中,输入的句子视为一个字符序列s={c1,c2,…,cn}∈Vc,其中,Vc表示字符集合,如式(1)~式(3)所示。
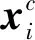
2.1.2 拼音特征
汉字存在多音的现象,对应同一汉字可以表现为不同读音,而读音的变化通常代表着汉字语义的改变。人们通过汉字发音的变化可以感知不同的语义,神经网络模型也可以借助拼音特征学习拼音到语义的映射。本文通过工具包pypinyin(2)https://pypi.org/project/pypinyin获得汉字字符对应的拼音,以拼音序列作为语料,使用Word2Vec训练得到拼音的向量化表示,如式(4)、式(5)所示。

2.1.3 五笔特征
拼音输入法是基于汉字发音,而五笔输入法基于汉字的结构。由于大量的汉字是象形文字,五笔输入法可用于找出潜在的语义关系以及单词边界。五笔相较于拼音可以得到不同层次的汉字语义,并且拥有相同结构的汉字组成词的概率更大,所以五笔有助于找到单词边界。本文通过官方五笔转换表(3)http://wubi.free.fr/index_en.html将语料中的汉字转换为五笔码,再使用Word2Vec训练得到五笔码到向量表示的映射,如式(6)所示。
(6)

2.1.4 单词级特征
基于字符的模型进一步融入单词级特征,有助于提升模型识别效果。单词级特征可以通过修改编码层模型的结构融入[15-16],也可以在嵌入层直接获取并融入到输入向量中[17]。本文选择在嵌入层融入单词特征,因为这种融入方式便于融合字符特征进行比较,并且单词特征与编码层模型的耦合度低,可以切换使用不同的编码器。
字符的单词级特征,对应为包含当前字符的单词集合,集合中单词的提取需要借助词表。其中,词表对应本文专利语料中未标注数据的分词结果去重后得到的单词列表,且分词过程中未引入额外的用户词典。单词特征的提取过程如下:
首先通过词表识别出字符序列中所有可能出现的单词,然后根据单词中字符出现的位置将其加入B、M、E、S四个单词集合,B、M、E、S分别代表字符出现在单词的开头、中间、结尾以及字符自身可看作单词。当集合中无匹配的单词,用None标记填充。如图2所示,字符“阻”对应出现在单词“高阻”的结尾以及单词“阻燃”和单词“阻燃性能”的开头,所以对应B={“阻燃”,“阻燃性能”},E={“高阻”};
且该句子中未匹配到中间包含字符“阻”的单词,同时字符“阻”无法独立成词,故M={None},S={None}。

图2 字符的单词特征提取示例图
在获得字符的单词特征后,对应每个字符的四个单词集合可以用如式(7)~式(10)所示。
在获取到字符的各单词集合后,通过注意力机制获取集合中各单词向量的权重,进一步对单词向量加权求和得到集合向量。其中,单词向量权重的大小等价于单词和输入句子之间的语义关联程度,语义关联程度通过句子向量和单词向量的余弦相似度进行度量。句子向量的通过BERT编码得到的各字符向量相加得到,由于BERT输出的字符向量维度大于单词向量的维度,句子向量需要通过一个全联接层投影到与单词向量相同的空间。单词集合S的向量表示的计算过程如式(11)~式(14)所示。
(11)
xj=ew(wj),wj∈S
(12)
(13)

(14)
其中,Ws,bs为训练参数,xs表示句子s的向量表示,ew代表单词向量查找表,as,j表示单词集合S中第j个词与句子的关联程度,m对应为集合S中单词个数,S表示单词集合S对应的向量。对应字符的单词特征向量,由包含它的四个单词集合的向量表示融合得到,如式(15)所示。

(15)
2.2 编码层2.2.1 BiLSTM
因循环神经网络(Recurrent Neural Network,RNN)具有共享参数、循环计算的运行模式,所以它能够有效地处理存在依赖关系的序列。在诸多改进的RNN结构中,BiLSTM因为能够处理长期依赖关系并且结合上下文进行编码的特点得到广泛的应用。本文将使用一个单层BiLSTM作为编码层模型,对前向LSTM(Long-short Memory Neural Network)计算过程的定义,如式(16)~式(18)所示。
(16)
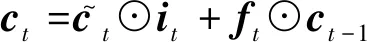
(17)
ht=ot⊙tanh(ct)
(18)

2.2.2 Transformer
Transformer通过自注意力机制获取序列中元素的上下文依赖关系,在诸多自然语言处理任务上取得了重大突破[18]。Transformer编码器由多头自注意力层和前馈神经网络层两部分构成,其中多头注意力层的基础是自注意力机制,自注意力机制的计算过程如式(19)~式(21)所示。
其中,Wq,Wk,Wq是将输入H投影到三个不同空间的参数矩阵,以上三个矩阵的大小都是d×dk,d代表输入的维度,dk是一个超参数,Qt是输入序列中第t个元素的查询向量,Kt是输入序列中第j个元素的键向量。多头自注意力使用多组Wq,Wk,Wq增强自注意力机制的效果,其计算过程定义如式(22)~式(24)所示。
其中,m代表参数矩阵Wq,Wk,Wq的组数,h代表参数矩阵的索引,WO代表大小为d×d的训练参数矩阵。多头注意力层的输出由前馈网络层进一步处理,处理过程如式(25)所示。
FFN(x)=max(0,xW1+b1)W2+b2
(25)
其中,W1,W2,b1,b2都是训练参数,W1∈d×dff,W2∈dff×d,b1∈dff,b2∈d,dff是超参数。
2.3 解码层
在NER任务中,解码层通常使用CRF模型一次对整个字符序列进行标签推理,如式(26)、式(27)所示。
其中,wy′,y和by′,y是联系于标签对(y′,y)的训练参数,ht表示编码层t时刻的输出,θ代表模型参数,Y(s)表示字符序列s对应的所有可能出现的标签序列。标签推理过程中,CRF在给定输入序列s的情况下,需要找出使得条件概率最大的标签序列y*,如式(28)所示。
y*=argmaxy∈Y(s)p(y|s;θ)
(28)
标签序列y*的查找问题可以使用维特比算法高效地解决。
本文提出一种融合多特征的功效短语识别方法,通过在模型嵌入层融合字符级和单词级特征提升识别效果,该方法的有效性在新能源汽车领域的功效短语数据集上得到了验证。
3.1 实验数据
本文数据来自于中国国家知识产权局数据库,以“新能源汽车”作为检索关键字,获得发明专利和实用新型专利共计25 717条。本文提取出所有专利的摘要进行分句,并过滤择其中的数字和英文字符得到原始语料共计54 305条句子。进一步,从原始语料中人工抽取出3 000条含有功效词的句子进行标注作为实验数据集。剩余的未标注数据与实验数据来自于相同领域,用于预训练Word2Vec和BERT。其中对BERT的预训练建立在Bert-base-Chinese已有的模型参数基础之上,进一步使用同领域的未标注数据在语言模型任务上调整BERT的模型参数,从而提高BERT在新能源汽车领域的泛化能力。功效短语数据集的统计信息如表1所示。

表1 功效短语数据集的统计信息
3.2 评价指标
本文选用与NER任务相同的评价指标,使用精确度(Precision,P)、召回率(Recall,R)和F1值(F1-score)评估本文方法。计算如式(29)~式(31)所示。
其中,TP、FP、FN分别表示识别出的功效短语个数、识别出的非功效短语个数以及未被识别出的功效短语。
3.3 对比实验
目前功效短语识别任务中效果最好的模型是CRF,CRF作为基线模型加入到对比实验之中,本文中CRF使用的特征模板源自马建红等提出的方法,但本文输入以字符作为输入单元,无法获取词性,所以用五笔特征和拼音特征替代原模板中的词性特征。对比实验中,编码层模型的对比涉及BiLSTM和Transformer,解码层模型则固定为CRF。为进一步验证特征融合的有效性,找到最有效的特征组合,在固定编码层和解码层模型的基础上,嵌入层切换使用不同的特征组合进行对比实验,特征组合设置如表2所示。

表2 嵌入层特征组合
3.4 实验参数设置
本文中Word2Vec模型调用gensim工具包实现,其中上下文窗口大小设置为5,向量维度设置为50,最小出现频次为1,其他参数为默认值;
BERT则是通过调用Transformers工具包实现适应目标语料领域的预训练以及字符向量化操作,该模型生成的字符向量维度为768。在模型训练过程中对于Word2Vec生成的向量和BERT模型参数都执行冻结操作,训练时不改变以上参数。
模型输入根据每个批次中句子的最大长度,对同批次中的其他句子使用

表3 模型超参数

续表
3.5 实验结果与分析3.5.1 对比实验
本实验的模型在服务器上使用GU进行训练,GPU型号为NVIDIA Tesla P4。在训练过程中,标注数据平均分为5份,按3∶1∶1的比例划分训练集、验证集和测试,每个模型使用交叉验证方法训练3次,最后模型的识别结果取平均值。实验结果见表4。

表4 对比实验结果
从表4可以看出,当编码器为Transformer,且输入特征为c_w2v时,识别结果的F1值最低。原因在于本文将功效短语识别转换为NER,而在NER中提取输入序列位置信息的能力有助于提升实体识别效果,BiLSTM因其循环计算的特点天然地可以捕获输入序列的位置信息,而Transformer则是通过引入位置编码向量尝试捕获输入序列的位置信息。本实验中训练数据规模小,使得Transformer中的位置编码向量无法精确捕获到序列位置信息,导致识别效果不佳。
除去以上情况,CRF模型的功效短语识别效果明显不及BiLSTM和Transformer等深度学习模型。进一步观察不同特征组合下深度学习模型的识别效果可以发现,在c_w2v+c_bert特征组合下,BiLSTM和Transformer识别效果有不同程度的提升,其中Transformer的识别效果提升显著。原因在于BERT使用了大规模的语料预训练语言模型,并且字符向量的生成过程基于整个输入序列,能够更准确地捕获字符的上下文语义信息和位置信息,从而提高下游模型的识别效果。
c_w2v+c_bert+w_att特征组合在BERT的基础上使用注意力机制引入单词信息,单词信息的引入有助于模型识别功效短语的边界,如表4所示,单词信息的引入使得BiLSTM和Transformer两种模型识别效果均有提升。
c_w2v+c_bert+w_att+c_py特征组合探究了字符拼音信息对功效短语识别的影响。但拼音特征的加入导致两类深度学习模型的识别效果都有所下降。原因可能在于拼音特征通过字符的多音现象只能识别字符相同但读音不同情况下的语义变化,无法识别字符读音相同但上下文语境不相同情况下的语义变化,带有以上局限性的拼音特征的加入反而可能混淆了融合后向量中的语义信息。
c_w2v+c_bert+w_att+c_wb特征组合探究了字符五笔信息对功效短语识别的影响。融入五笔特征后,两类下游模型的识别效果有小幅度的提升,因为以上其他特征都忽略了字符结构对识别效果的影响,而五笔特征能有效获取字符结构信息。
综上所述,BiLSTM能更好地捕获序列位置信息,BERT预训模型生成的向量蕴含更丰富的语义信息和位置信息,有助于提升下游模型的效果。在加入预训练模型的基础上,单词信息和字符五笔信息的加入能进一步提升功效短语的识别效果。所以,嵌入层使用特征组合c_w2v+c_bert+w_att+c_wb,编码层使用BiLSTM,解码层使用CRF,在本文中能够得到F1值91.15%的最佳识别效果。
3.5.2 BERT训练方式对实验结果的影响
本文中BERT训练方式分为两类:
①在NER阶段之前,使用未标注的同领域语料在语言模型任务上进一步预训练BERT模型。②在NER阶段,使用标注语料在NER任务上微调BERT模型。为验证不同的BERT训练方式对实验结果的影响,选取LSTM+CRF作为编解码器,c_w2v+c_bert作为输入的特征组合,进行对比实验,实验结果如表5所示。
根据表5中实验结果可以看出,在NER阶段前,使用同领域语料在语言模型任务上预训练BERT,最终模型的识别效果最好。以上结果表明,在NER任务标注数据规模较小时,相较于使用少量标注数据微调BERT,使用更大规模的未标注的同领域数据预训练语言模型,更能提高BERT在当前领域下的泛化能力,从而提高下游NER任务的识别效果。

表5 不同BERT训练方式对比实验结果
3.6 样例分析
表6为基于BiLSTM+CRF模型,加入拼音特征前后识别功效短语的两个样例。从表6中可以观察到,在嵌入层加入拼音特征后,反而导致样例1中的功效短语“整车重量”和样例2中的功效短语“扭矩载荷”无法识别。

表6 拼音特征加入前后,功效短语识别样例
表7为基于BiLSTM+CRF模型,使用不同特征组合识别功效短语的一个样例。从表7的功效短语识别样例中可以看出,模型使用c_w2v+c_bert+w_att+c_wb特征组合识别出的功效短语与参考功效短语完全一致,使用其他特征组合识别的功效短语相较于参考功效短语都有一定程度的缺失。其中缺失最多的为“节能”这一功效短语,原因在于语料中较少使用“明显”修饰技术功效短语,而 c_w2v+c_bert+w_att+c_wb特征组合中字符五笔信息的加入增强了低频字符的语义表示,从而能够识别出与之关联的功效短语。

表7 功效短语识别样例

续表
为提高专利功效短语识别的效果,本文提出了一种融合多特征的功效短语识别方法。该方法在模型嵌入层融合了字符、字符五笔和字符拼音等字符级特征,其中字符级特征的向量化兼顾了BERT预训练模型和Word2Vec模型。在此基础上,为补足基于字符输入的模型缺少单词信息的短板,使用注意力机制将词表匹配得到的对应字符的单词集合向量化后,与各字符级特征向量表示融合为最终的输入向量,语义更加丰富的输入向量提高了模型识别的效果。实验结果表明,与传统的CRF模型和未融合多特征的深度学习方法相比,本方法有效提高了专利功效短语的识别效果。
猜你喜欢 字符语料短语 基于归一化点向互信息的低资源平行语料过滤方法*通信技术(2021年12期)2022-01-25论高级用字阶段汉字系统选择字符的几个原则汉字汉语研究(2020年2期)2020-08-13字符代表几小学生学习指导(低年级)(2019年12期)2019-12-04一种USB接口字符液晶控制器设计电子制作(2019年19期)2019-11-23图片轻松变身ASCⅡ艺术画电脑爱好者(2019年8期)2019-10-30《健民短语》一则海峡姐妹(2016年2期)2016-02-27《苗防备览》中的湘西语料民族古籍研究(2014年0期)2014-10-27国内外语用学实证研究比较:语料类型与收集方法外语教学理论与实践(2014年2期)2014-06-21基于统计的中文词法分析应用">异种语料融合方法:基于统计的中文词法分析应用中文信息学报(2012年2期)2012-06-29 相关热词搜索:短语,功效,融合,






