心理学视野下的社会变迁研究:研究设计与分析方法*
时间:2023-04-07 22:35:03 来源:千叶帆 本文已影响人
蔡华俭 张明杨 包寒吴霜 朱慧珺 杨紫嫣 程 曦 黄梓航 王梓西
(1 中国科学院心理研究所行为科学重点实验室,北京 100101) (2 中国科学院大学心理学系,北京 100049)(3 清华大学新闻与传播学院,北京 100084) (4 成都大学心理健康教育中心,成都 611730)
社会变迁作为人类社会发展过程中的重大科学问题(中国科学报,2019),正在成为心理学的前沿热点(Varnum &Grossmann,2017,2021)。心理学视角的社会变迁研究关注的是在社会变迁过程中人类的文化、心理和行为在时间维度上的变化。具体地,常涉及几个方面的问题,比如怎么变(变化的内容和方向)、为什么变(导致变化的原因)、如何变(变化的过程和机制)等。对于当下中国来说,对前两个问题的研究更具现实意义,也更为紧迫。鉴于在研究与人类心理变迁相关问题时,经常需要采用和研究其他心理学问题不同的方法,我们拟对和这两个问题相关的常见研究设计和数据分析方法进行介绍,帮助国内研究者了解这些设计、方法及其独特性,从而促进国内的相关研究。为了便于理解,我们先对社会变迁研究中常见的三种效应进行简单介绍。
和发展心理学类似,社会变迁研究通常涉及三种效应(Bell,2020;Fosse &Winship,2019):年龄效应(age effect)或成熟效应(maturation effect)、时间效应(time effect)或时期效应(period effect)、时代效应(cohort effect)或世代效应(generation effect)。其中,年龄或成熟效应是指由个体发展导致的效应(比如:改革开放期间中国人的心理和行为的自然成长导致的变化),时间或时期效应是指与特定时期内发生的各种社会事件导致的效应(比如:改革开放对中国人的影响),时代或世代效应是指和特定出生年代有关的效应(比如:改革开放对不同年代出生的中国人的不同影响)。在任何一个时间点上,个体的心理和行为都是这三个效应共同作用的结果。
和发展心理学主要关注年龄效应不同,在社会变迁研究中,研究者关心的通常是时间效应和时代效应,而年龄效应则是需要控制和排除的噪音。理想中,大家都期望能够对所涉及的效应进行区分和分别估计。实际中,目前还没有一种方法可以在不预设任何前提的情况下对上述三种效应进行准确估计(Bell,2020;Dinas &Stoker,2014;Rudolph et al.,2020),因为年龄、时间和时代三者可以互相线性表达(年龄=时间 -出生年),以致上述效应的两种或三种经常混淆在一起。社会变迁研究的这一特点要求我们对每一种研究设计的优缺点、所涉及的效应有清醒的认识,并借助相应的理论对结果做出尽可能合理的解释。下面在介绍每一种具体的研究方法时,我们会特别指出每一种方法所涉及的效应,供读者参考。
研究个体或群体心理和行为如何随着时代的发展而变化,最直接的方法就是在不同时间点对目标个体或群体心理和行为进行调查,然后进行跨时间比较,继而以先后时间点上的心理和行为的差异为基础来推测其在时间维度上的变化。不过,社会变迁是一个漫长的过程,很多研究并非事先计划,采集跨时间数据的现实可行性有限。因此,在跨时间数据缺乏的情况下,研究者也经常利用非跨时间或横断面的数据来间接推测变迁规律。此时,常用的方法有两种:跨代际比较和跨地区比较。跨代际比较是通过某一时间点上的不同代际之间的心理和行为差异来推测心理和行为的变化趋势。这里一个重要前提假设是,老一代代表着过去或传统社会,而新一代代表着当下或现代社会,这样就可以通过代际之间的差异来推测传统社会和现代社会之间的差异,进而推测社会发展过程中人类心理和行为可能发生的变化。而跨地区比较则是通过某一时间点上处于不同发展阶段的地区之间的人们的心理和行为差异来推测心理和行为的变化趋势。这里一个重要前提假设是,欠发达地区(比如农村)代表着过去或传统社会,而发达地区(比如城市)则代表着当下或现代社会;这样就可以通过不同发展阶段的地区之间的差异来推测社会发展带来的心理影响。下面我们依次介绍跨时间比较、跨代际比较、跨地区比较的各种方法和范式。
2.1 跨时间比较
跨时间比较有3 种主要方法,分别基于3 种不同来源的数据:历史档案数据、既往发表文章报告的数据、各种调查数据。其中,前两类数据都是群体水平的,反映的是宏观水平上的群体特点的变化。最后一类数据是个体水平的,所有相关个体变量都可以纳入分析,因而可以探讨心理和行为变化是否随着个体特征的不同而不同。下面我们分别对这三种方法进行介绍。
2.1.1 基于档案数据的跨时间分析
社会变迁研究中常用的档案数据主要有两类:第一类是数字形态的历史统计数据,如国家统计局等机构发布的统计年鉴等;第二类是非数字形态的文化产品,如Google 图书资料库(Google Books Ngram Corpus)、历年流行歌曲的歌词、影视剧本、报刊资料、人名数据库等。
对于数字形态的历史统计数据,研究者可以直接通过分析数据和年代之间的关系来揭示数据所代表的心理和行为随时间变化的规律。常用的数据指标有离婚率、家庭规模、家庭多代同堂率等,这些数据都是社会变迁的重要标志。在心理学中,上述指标常作为个体主义和集体主义的客观指标,用来探讨文化心理的变化。比如,有研究采用这些指标对全球很多国家的文化变迁趋势进行了研究,结果发现,在全球范围内,个体主义在上升,而集体主义在下降(Santos et al.,2017)。
对于非数字形态的文化产品,研究者首先需要对这些文化产品中包含的具有特定心理含义的部分(通常是字或词)进行量化,然后分析其和年代之间的关系。在目前的社会变迁研究中,量化的信息通常有两类,一类是代表某种文化心理(比如个体主义)或现象的流行情况,通常用代表该心理的词每年出现的频率来表征,这类信息可以用来研究该文化心理现象流行情况的变化。目前社会变迁研究中绝大部分基于非数字形态的研究都属于这类研究。比如:基于Google Books Ngram语料库,有研究通过调查9 种语言中第一人称单数代词(“我”)和第一人称复数代词(“我们”)的使用情况,进而考察不同国家或地区的个体主义和集体主义价值观在过去半个多世纪的变化趋势(Yu et al.,2016);基于流行歌曲歌词,有研究通过对歌词中自我词和情绪词的变化,进而考察文化取向和情绪的变迁(Berger &Packard,2018);基于名字库,有研究通过分析名字独特性的变化趋势,进而推测个体主义文化的变化趋势(Bao et al.,2021;Bianchi,2016);基于广告语,有研究通过分析广告和电视内容中价值观信息的变化,进而推测人们价值观的变化(Lin,2001);基于电视节目,有研究通过分析流行电视节目内容包含的个体主义信息的变化,进而推测个体主义的变化(Uhls &Greenfield,2011)。
另一类量化信息通常是代表某种文化或心理现象的目标概念(比如个体主义)的特征,通常用目标概念和其他属性概念(比如积极和消极)之间的联系来表征。这种联系通常反映的是一种内隐联系,比如内隐态度(比如对个体主义的内隐态度)或内隐刻板印象(比如女性和家庭相联的刻板印象);其变化在一定程度上可以反映某目标概念的含义或相应联系的变化。比如,一项最新的研究中,研究者利用自然语言处理的词嵌入(Word Embedding)技术对Google Books 中文书籍中的个体主义和积极或消极概念的联系进行了量化,结果发现从1950 年到1999 年间,个体主义与消极词的联系在减弱,表明个体主义在中国的接受程度在上升(Bao et al.,2022;Hamamura et al.,2021)。此外,该研究还发现个体主义和工作之间的联系强度没有变化,和金钱词的联系在不断加强。这些结果表明,个体主义或集体主义在中国的涵义过去几十年来既有稳定的一面、也有变化的一面。还有研究基于Google Books、Google News 等语料库探讨了女性概念和工作之间的联系在 1910 年和1990 年间的变化,结果发现,女性和工作的联系在不断上升,表明职业的性别刻板印象在减弱(Garg et al.,2018)。
使用档案数据进行文化变迁研究具有一些优点。首先,档案数据内容丰富、跨时也可以较长,可以用来研究很多变迁现象,不仅包括心理和行为本身流行情况的变化,还包括其内涵的变化;和相关社会生态变量结合起来还可以探讨导致变迁的社会生态原因。其次,数据多来源于真实情境,大多都不是为研究专门设计的,研究结果的生态效度较高(Kashima,2014)。但是,这类研究也存在不足(Heng et al.,2018)。首先,这些数据并非为研究而设计,分析对象未必能很好地代表对象总体,以致使结果的可推广性受限(Varnum &Grossmann,2017)。其次,研究结果虽然不涉及年龄效应,但是结果通常是时间效应和时代效应的混合,无法对二者做进一步的区分。再次,源自档案内容的心理指标的效度在一定程度上会限制结果的有效性。最后,数据可能涉及被试隐私,违反研究伦理(Verma,2014)。
2.1.2 基于既往发表数据的横断历史元分析(crosstemporal meta-analysis,CTMA)
横断历史元分析是一种用来研究社会变迁的特殊的元分析方法,由Twenge 于1997 年首次提出并应用(Twenge,1997;详细介绍见: 辛自强,池丽萍,2008)。与一般元分析类似,横断历史元分析也是一种对过去发表的研究数据进行汇总和定量分析的方法;但与一般元分析不同,在横断历史元分析中,研究者关注的不是心理效应的汇总,而是心理特征的平均水平如何随年代的变化而变化。研究者通常以过去发表的某一主题的所有研究中涉及的样本均值(或中位数)作为分析对象,通过考察这些样本均值和年代的共变关系来揭示其变化情况。
进行横断历史研究通常涉及建立数据库和数据分析两个阶段。与常见的元分析过程相似,数据库的建立主要有以下几个步骤:(1)搜索符合研究目标、并且具有可比性的文章(群体、测量工具相同或具有可比性);(2)根据一定的纳入标准(例如该文献是否报告了被试的量表得分均值)对文献进行筛选;(3)文献编码;(4)按照时间顺序整理研究;(5)复查文献编码信息,确保数据质量。在数据分析阶段,先要对数据有关信息进行描述和展示,包括来源、样本量、均数、标准差、分布等;然后重点考察研究的心理变量与年代之间的共变关系;有时还可以通过继续考察有关社会生态变量(比如GDP、流行病发生率等)和心理变量的共变关系进一步探讨导致心理变化的可能社会生态原因(辛自强,池丽萍,2008)。
国内外已经有很多研究采用横断历史元分析探讨了各种文化心理的变迁。1997 年,Twenge 等第一次运用横断历史元分析对美国在1975~1994年间性别角色的变迁进行了研究,结果发现,美国女性越来越有男性化的倾向,而男性却越来越有女性化的倾向(Twenge,1997)。在国内,Cai 等最近对中国人在2001~2019 年间的幸福感进行了横断历史元分析,结果发现中国人的幸福感自2001年来呈线性上升趋势;研究还通过时间序列分析发现,经济增长是导致中国人幸福感上升的重要原因(Cai et al.,2022)。
横断历史元分析利用过去发表的数据来探讨心理与行为的变化,具有许多优点。首先,横断历史元分析对以往发表的数据重新利用,成本低,一定程度上克服了变迁研究所需的历史数据难以获得的困难;其次,横断历史元分析可以通过考察不同年代中来自同一年龄阶段的被试的数据(比如大学生)从而控制年龄效应。当然,横断历史元分析也有不足。首先,不是所有的心理变量都有跨时足够长的可比较的数据,因此该方法能够研究的问题有限。其次,虽然横断历史元分析可以控制年龄效应,但是时间效应和时代效应依然混合在一起,并有可能高估或低估时代效应(Rudolph et al.,2020);最后,由于不同年代的数据来源于不同样本,样本的代表性和样本间的可比较性不一定可以保证,以致结果的可靠性和可推广性受限(Trzesniewski et al.,2008)。
2.1.3 基于调查数据的跨时间分析
第三种跨时间的分析是以各种个体水平的实际调查数据为基础。这些调查由于最初的调查目的、可操作性等的不同存在很多不同的设计。下面,我们根据设计的不同对各种方法进行介绍。
(1) 横断序列设计(cross-sequential design)
基于横断序列设计的研究,在每个时间点上调查一个独立样本,通过对不同时间点采集的独立样本数据在时间维度上进行对比分析,继而推测心理和行为的变化。许多大型的社会调查采用的就是这种设计,比如世界价值观调查(World Values Survey,WVS;http://www.worldvaluessurvey.org/wvs.jsp)、中国综合社会调查(China General Social Survey,CFPS;http://cgss.ruc.edu.cn/)、盖洛普世界民意调查(Gallup World Poll,GWP;https://www.gallup.com/home.aspx)等。这种设计在社会变迁研究中有很多成功的应用,产生了许多重要发现。比如,利用GWP 在2005~2019 年间的社会流动性数据,对全球167 个国家的社会向上流动性的变化趋势及导致其变化的社会生态原因进行了分析,结果不仅揭示了各个国家的基本变化趋势及其复杂性,还发现教育私有化是变化的重要解释变量(Chan et al.,2021)。Cai 等(2022)对包括GWP、WVS、CFPS 在内的所有涉及中国人的幸福感的公开调查数据进行了整合分析,结果发现从1990 年到2018 年,中国人的幸福感表现出“U”型变化趋势,先降后升,但总体上依然是上升的基本趋势。除了跨时较长的研究,还有跨时很短的横断序列研究。比如,Park 等人(2016)对美国经济衰退前(2004~2006 年)和衰退期(2008~2010 年)大学生的价值观进行了对比,结果发现美国大学生的社群主义(communitarianism) 和物质主义(materialism)在经济萧条期间都有所增加(Park et al.,2016)。
横断序列设计有许多优点。首先,不同时间点上的样本可以不一样,数据获取相对容易;其次,理论上讲,可以研究一切能够通过调查进行测量的心理和行为,因此适用范围非常广;再次,可以把个人水平和群体水平的变量结合起来进行多水平分析,基于一定的假设,还可以对年龄效应、时间效应和时代效应进行分解(Yang &Land,2008)。不过,横断序列设计在每一个时间点上调查的是不同的样本,这些样本是否具有代表性、是否具有可比性是不可忽视的问题。
(2) 纵向追踪设计(longitudinal design)
纵向追踪设计通常锁定一个样本,然后进行多年的追踪调查,在每个设定的时间点收集所有被试的数据。纵向追踪设计可以是很短期的,也可以跨时相对较长。当采用时代-序列追踪设计(cohort-sequential longitudinal design),样本将会包含不同出生年代的人。此时,如果数据点较多,基于一定的假设,可以对年龄效应、时间效应、时代效应进行较好的分解(Yang &Land,2008)。
例如,Twenge 等对美国人的自尊在 1986~2002 年间的变化进行了研究。基于出生在不同年代的被试(从25 岁到104 岁)的四波大样本追踪测量数据(1986,1989,1994,2002 年),通过运用多水平分析模型对数据进行建模分析(Yang &Land,2008),结果不仅揭示了美国人的自尊随年龄增长而变化的发展曲线(先增后降,60 岁左右到达顶峰),还发现了显著的时间效应和时代效应,1960年后出生的被试的自尊在1986~2002 年间呈上升趋势,但是此前出生的被试的自尊在这段时间内呈不变或下降趋势(Twenge et al.,2017)。在一项最近的研究中,基于美国国家青年追踪研究(National Longitudinal Study of Youth)数据,Hong等对出生于1980~1984 年间的5 代被试在美国2008 年的经济大萧条前后就业和就学情况影响进行了研究。结果不仅发现了显著的时代效应和年龄效应,更发现显著的时间效应,即大萧条作为宏观社会经济条件对青年的就业和就学情况产生了显著影响(Hong &Chung,2022)。
纵向追踪研究的一个优点是,每次研究调查的是同一批被试,可以避免不同时间点由于被试的不同而未必可比的问题;其次,基于一定的假设和恰当的统计分析,可以对年龄效应、时间效应和时代效应进行一定程度上的分解,从而可以分别考察不同的效应。但是,这种方法数据采集很困难,被试流失是一个常见的问题;还有,由于其只是调查一个有限的样本,结果准确性、可靠性受样本大小和代表性影响较大;最后,由于是追踪研究,不适合跨时长的变迁研究。
(3) 循环追踪设计(revolving panel design)
循环追踪设计和一般追踪设计类似,需要在多个时间点上进行数据采集,不同的是,不同时间点的被试不完全相同,从第一次数据采集开始,以后每一次数据采集都有一些原有的被试流失,同时又有一些新的被试加入,因此两个不同时间点的被试部分相同、部分不同。全美犯罪受害调查(National Crime Victimization Survey,NCVS)采用的就是这种研究设计。该调查项目自1973 年开始实施,每半年一次,对全美具有代表性的家庭进行访谈,调查过程中会不断有家庭退出和加入,从而形成循环追踪设计。家庭中所有符合条件的成员会被访谈七次(即共3.5 年),以了解他们在过去半年内经受的各种形式的暴力行为。有研究者利用1973 年至2010 年全美犯罪受害者调查的数据,对男性暴力受害与其人口学特征之间的关系进行了研究,发现白人男性与黑人男性、拉丁男性的暴力受害经历之间的差异在很大程度上能够被年龄、居住地、经济和工作情况所解释,而种族、民族与受害经历之间的关系并未随着时间变化发生显著的改变(Lauritsen et al.,2018)。
循环追踪设计是纵向追踪设计和横断序列设计的结合,因此除了二者共有的特点外,还有一些独特的优点。比如,研究者可以对追踪的样本和非追踪的样本分别分析,从而对结果进行交叉论证,增强结果的可靠性。
(4) 全样本设计(total population design)
顾名思义,全样本设计就是在每个时间点上都对研究设定范围内的所有被试进行数据采集。每隔一段时间进行一次的国家人口普查就是这种设计的典型应用。由于每年都会有一定的出生和死亡人口,每次人口普查的样本都会有些不一样。其中,多个时间点共有的被试可以进行类似纵向追踪研究的建模分析;而非共有的数据则可以进行类似横断序列设计的跨时间的横断对比分析。目前,有不少基于人口普查数据发表的社会变迁研究,比如有研究通过分析美国人口普查数据,发现文化规范变化会影响家庭生育率(Hacker &Roberts,2017)、城市化会影响家庭世代同居情况的变化(Merchant et al.,2012;Pensieroso &Sommacal,2019)以及男、女经济地位的变化会影响婚姻情况和家庭权力(家长制) (Ruggles,2015)等。
全样本设计是循环追踪设计的升级版,除了循环追踪设计的一般特点外,还具有样本大、代表性强的优点。但是这样的调查通常涉及的心理内容非常有限,且实施需要耗费巨大的人力和物力,在心理与行为的社会变迁研究中实际作用有限。
(5) 回溯性追踪设计(retrospective panel design)
回溯性追踪设计和纵向追踪设计类似,拥有一个特定的被试样本,以及每个被试在不同时间点的数据;不同的是,每一个时间点的数据都不是对被试在那个时间点的真实测量,而是基于后来的回溯性记忆给出的估计。很多时候,该方法让来自不同出生时代的参与者回忆曾经的经历和心理状况,并以时间序列的形式记录编码,从而重建个体心理和行为的连续数据,然后以这样的连续数据为基础,进而考察社会变迁的影响。德国生命史调查就是基于这种方法。有研究者利用德国的这个调查数据进行分析发现,阶级出身和受教育程度之间的联系正在减弱,即教育不平等程度在减弱(Breen et al.,2009,2010)。在中国,张明杨(2021)运用回溯性追踪设计对一批55 岁以上的被试进行了调查,让他们基于回忆对80 年代初、2000 年初和现在的中国人的理想情绪进行评估,结果发现中国人对高唤醒积极情绪和低唤醒积极情绪的偏好都在上升。
回溯性追踪设计具有纵向追踪设计的一些优点,同时也避免了纵向追踪设计需要在每一个时间点采集数据的麻烦,使得数据采集相对较为容易。但是,这种设计以被试的回忆为基础,存在许多其他设计没有的问题。比如,被试是否能够准确记得过去;即使记得,是否愿意如实报告;即使能够回忆并愿意报告,各种记忆偏差(如选择、重构、简化、扭曲等)将会造成什么样的影响;即使到了最后,对被试回忆内容的人工编码有时也会出现偏差。所有这些偏差最终都会反映到结果中,从而降低结果可靠性。
2.2 跨代际比较
出生在不同年代的人,由于人生历程中所经历的社会环境和历史事件通常不同,因而身上会带有不同的时代烙印,从而为我们研究社会变迁对心理和行为的影响提供了新的可能(Cai,et al.,2018;Gilleard,2004;Joshi et al.,2011;Schuman &Scott,1989)。
一种常见的跨代研究设计是,根据某种标准对客观年代进行划分,然后对出生在不同年代的人的心理和行为差异进行对比,继而通过代际间的差异推测心理和行为的变化。具体研究中,定义和区分“代”的常见方法有两种。最简单、直接的一种就是按照年代进行划分,每隔一定年为一代,例如,出生在1960 年至1969 年的为一代、出生在1970 年到1979 年之间的为一代(廖小平,张长明,2007;刘凤香,2011;刘苹 等,2012)。另一种则是以关键的历史事件为依据进行划分,例如,Tang 等(2017)为了研究经济发展对于不同出生年代的员工的价值观的影响,按照两个重要的经济事件(1978 年的改革开放、1990 年上交所和深交所的成立)将研究对象分为三代:改革前一代(出生在1978 年以前)、改革一代(出生在1978~1989 年)、改革后一代(出生在1989 年以后)。不管是哪种方法,属于同一代的个体应该有类似的社会经历,因此身上会带有一些类似的时代烙印。
另外一种常见的跨代研究设计则不以客观年代为标准,而以某一时间点上的家庭为分析单元,以直系亲属关系为基础,以祖父母辈、父母辈和子辈三代为基础进行家庭代际差异研究。这样,通过上下三代或两代人的差异来推测心理和行为在时间维度上的变化趋势。比如,为了调查玛雅地区从农业社会发展到商业社会人们价值观的变化,Manago (2014)对18 个高中生及其母亲、祖母进行了访谈,通过代际差异分析,作者推断个体主义呈上升趋势,而集体主义呈下降趋势。Zhou 等对祖父母眼中的中国三代孩子的心理特点(自主、好奇;服从、害羞等)以及三代父母的养育风格(支持、表扬;控制、批评)的看法进行了访谈,结果发现,年轻一代具有更多的个体主义心理特点和养育风格(Zhou et al.,2018)。
两种跨代设计得到的所谓代际差异是年龄效应、时代效应的混合,无法确知差异来源。但是,两者的一个共同优点是一次调查就可以获得全部数据,相对容易实施。家庭代际差异研究还有一个独特的优点,即不仅可以用来考察不同代际之间的差异,还可以用来考察不同代际间的相似性或代际传递。
衡量家庭内代际相似性有三种方式,第一种是代和代之间的绝对均数差,差越小,表明相似性越高;第二种是代与代的相关系数,相关越高,表示相似性越高;第三种则是代与代之间多个心理特征的模式或剖面相关(profile correlation),相关越高,表示相似性越高。这三种相似性指标反映代际差异或相似性的不同侧面。第一种代际之差反映的是代际的绝对平均差异;
第二种和第三种代际相似性反映的则是相对差异,即来自不同家庭的父代与子代在整个样本中相对位置的不变性。特别需要注意的是,绝对平均水平的差异大小和代际相似性相对独立,这意味着,代际相似性高并不必然表示绝对平均水平不存在代际差异,同样,代际相似性低并不必然意味着绝对平均水平差异很大。一项发表在Science杂志的涉及祖孙三代的研究发现,人类的文化可以通过包括代际间的垂直传播在内的多种方式进行传递,并且文化观念传递性因领域而异(Cavalli-Sforza et al.,1982)。
2.3 跨地区比较(历史重构法)
跨地区比较研究需要对两个或多个处于不同发展或现代化水平不同的地区的人群进行同时考察,再通过对不同发展水平或阶段的地区进行横断对比,继而推测社会发展的一般趋势。跨地区比较可以在不同发展水平的国家间进行比较,也可以在一个国家内部发展水平不同的地区进行比较。比如,Xin 等通过对考察中国29 个省份间信任水平的差异,发现越是发达的、市场化水平高的地方,信任水平越低;由于中国过去几十年来总体上市场化水平在不断提高,他们推测中国人的信任过去几十年来在不断下降(Xin &Xin,2017)。Cai 等(2012)在一项关于自恋的大样本研究中发现中国城里人的自恋水平比农村人高,据此以及其他一些证据,他们推测中国人的自恋在现代化进程中有日益增高的趋势。
横断比较法不需要采集跨时间点的数据,能以较低成本、更方便地了解人类文化、心理和行为的变化规律及背后原因。但是,横断比较中,比较的是不同的样本,样本代表性和可比较性将会影响结果的可靠性。还有,从地域差异推测时间变化差异是以前述的一些重要假设为基础,当假设不能得到满足时,结果将可能不准确或不可靠。
社会变迁研究中大家最为关心的是某种心理或行为的变化趋势及影响变迁的社会生态原因。对此,传统的统计分析方法是简单相关和回归分析。当以时间作为预测变量时,就可以揭示变迁趋势;当以潜在社会生态变量作为预测变量时,则可以探索导致变迁的可能原因。但是,由于简单相关和回归分析在处理具有时间序列性质的数据无法排除自相关和虚假相关的影响,越来越多的研究开始采用时间序列分析,特别是交叉滞后相关和格兰杰因果检验。下面我们先介绍传统分析方法及其局限性,然后重点介绍现代时间序列分析。
3.1 传统分析方法及其局限性:自相关和伪相关问题
在社会变迁研究中,研究除了收集感兴趣的心理和行为的年度数据,通常也会收集对应年份的社会生态变量,如人均GDP、城镇化率、传染病流行率、自然灾害频次等。在考察心理和行为的变迁趋势时,通常是把该心理和行为作为结果变量,把时间作为预测变量,建立回归方程,从而分析心理和行为如何随时间的变化而变化。如果要进一步考察导致变化的可能原因,则可以把潜在社会生态变量作为预测变量建立一元或多元回归方程,进而了解各生态变量的预测或解释作用。
但是,传统的回归分析在处理社会变迁数据时存在许多问题。社会变迁研究中收集的数据很多都是时间序列数据,而时间序列数据往往存在自相关(autocorrelation),即变量在时间维度上存在连续性,相邻观测之间不独立,某一年数据与前一年甚至前若干年的数据之间存在相关性。自相关的存在使得分析的数据通常不满足传统的回归分析对误差独立性的基本要求,使得回归系数标准误的估计出现偏差,相应的假设检验结果可靠性降低。
此外,传统的回归分析还无法解决伪相关(spurious correlation)问题,即分析揭示的某两个变量的相关可能是由某个第三变量导致的虚假相关。这里的第三变量可能是时间本身,或者未被观测到的其他社会生态变量等(Neusser,2016)。比如,生活中很多家长都有一个感觉,孩子上课外辅导班越多,将来上好大学的可能性越高。表面上看,上课外辅导班可以提高孩子上好大学的可能性似乎是对的。但是,二者的相关可能是背后的家庭经济条件导致的:家庭经济条件好的孩子更有可能上辅导班,也有更大的可能性上好大学。这种情况下,上辅导班和上好大学的相关其实只是一个虚假的相关,导致二者产生相关的真正原因是家庭经济条件。可见,对于社会变迁研究中的时间序列数据,尤其是存在共变趋势的时间序列,传统回归分析得到的结果很可能只是一种伪相关,从而导致错误的结论。此外,传统的回归分析得到的两个变量的关系即使真的存在,也只是一种相关关系,无法确定其因果,因为二者是同时发生的。为了排除自相关和伪相关对结果的影响,并探讨变量间可能的因果关系,更合适的是进行时间序列分析(Box-Steffensmeier et al.,2014)。
3.2 时间序列分析
时间序列分析是一种涉及时间变化的分析方法的统称,通常用来研究一个或多个变量如何随时间变化,同时如何受其他变量变化的影响等问题,在金融学、经济学等领域有广泛应用(Box-Steffensmeier et al.,2014;Neusser,2016)。近年来,越来越多的心理学研究也开始采用时间序列分析,其中一个重要的领域就是社会变迁研究(如Grossmann&Varnum,2015)。
时间序列分析使用的是一组按照一定时间间隔(如天、周、月、季度、年)排列起来的对某个特定对象(如一个国家)的观测数据。时间序列分析一般要求具有50 个时间点的观测数据,最少不能低于20 个(Jebb et al.,2015)。时间序列分析还要求数据满足一些前提条件。其中,最重要的一个条件是平稳性(stationarity):如果一个时间序列的均值、方差、自相关系数等统计特征不随时间推移而变化,那么就称其为平稳时间序列,否则为非平稳序列(Neusser,2016)。也就是说,一个明显呈上升或下降趋势的时间序列,不具有平稳性,不能直接使用其原始值进行后续的时间序列分析,而是要事先去除时间趋势,使时间序列平稳化。在统计上,用于检验时间序列是否平稳的方法包括:(1)检查时间序列图,直观判断是否存在明显的趋势或周期,有趋势或周期的时间序列都是不平稳的(Jebb et al.,2015);(2)检查自相关图,平稳时间序列通常具有短期相关性,随着时间期数的增加,平稳序列的自相关系数会很快衰减趋向于零;(3)单位根(unit root)检验,如Augmented Dickey-Fuller (ADF)单位根检验,如果存在单位根,则说明时间序列不平稳;(4)平稳性检验,如KPSS 检验(Box-Steffensmeier et al.,2014)。如果发现时间序列不平稳,可以对数据进行适当转换使时间序列平稳化。一种常用转换方法是对原始数据进行一阶差分(first-order differencing),即用T 年的数据减去T -1 年的数据得到一系列差值作为新的时间序列,该新数据反映的则是相较于前一年的年度变化量(Levendis,2018)。如果一阶差分后仍然非平稳,可以进一步做高阶的差分。需要注意的是,随着阶数的增加,新时间序列的实际意义将会越来越难解释。如果希望去除时间趋势和混淆变量的影响,还可以在回归中使用时间趋势项和混淆变量预测某个时间序列,然后保存回归的残差(residuals),后续的分析则以残差构成的新的时间序列为基础(如Caluori et al.,2020;Jackson et al.,2019)。
3.3 双变量时间序列分析方法
目前,社会变迁研究中用的最多的是双变量的时间序列分析。其中,一个变量通常为心理或行为变量,另一个通常为社会生态因素。这种情况下,通常把一个变量作为结果变量,另一个变量作为预测变量。
3.3.1 交叉滞后相关(cross-lagged correlation)
假如有两个平稳时间序列变量X 和Y,要考察究竟是X 的变化先于Y 的变化,还是反方向的关系,可以进行交叉滞后相关分析,得到两个变量的交叉相关函数(cross-correlation function,CCF)和交叉相关图(cross correlogram)。具体而言,CCF依次计算时间序列Y 和X 同期及X 滞后1~k 年的简单相关(k 一般设为20 或30),将求得的若干相关系数视为滞后期数(从-k 至k)的函数;以相关系数为纵坐标、滞后期数为横坐标,得到交叉相关图(见图1),一般将Y 和X 过去项的相关系数绘制在图的-k 至-1 范围(左半侧),将Y 和X 滞后项的相关系数绘制在图的1 至k 范围(右半侧),而两者的同期相关系数则是在图中间。通过交叉相关图,可以找出相关系数绝对值最大的滞后期数:如果在左侧,则说明当前的Y 与过去的X 相关最高,意味着X 的变化先于Y 的变化(图1A);如果在右侧,则说明当前的Y 与滞后的X 相关最高,意味着X 的变化滞后于Y 的变化(图1B);如果最高相关在图中间,则说明X 和Y 的同期相关最高,无法通过交叉滞后相关分析得出X 和Y 的变化谁先谁后的结论(图1C) (Neusser,2016)。同时,交叉相关图中绝对值最大的相关系数的方向和大小也需要参考,相关的正负号代表了X 和Y 关系的正负向,而相关的大小代表了关系的强度;此外,能进行CCF 分析的软件(如R 语言的ccf 函数)还会在图中给出恰好达到统计显著的相关系数的参考线(见图1 中的蓝色虚线)。
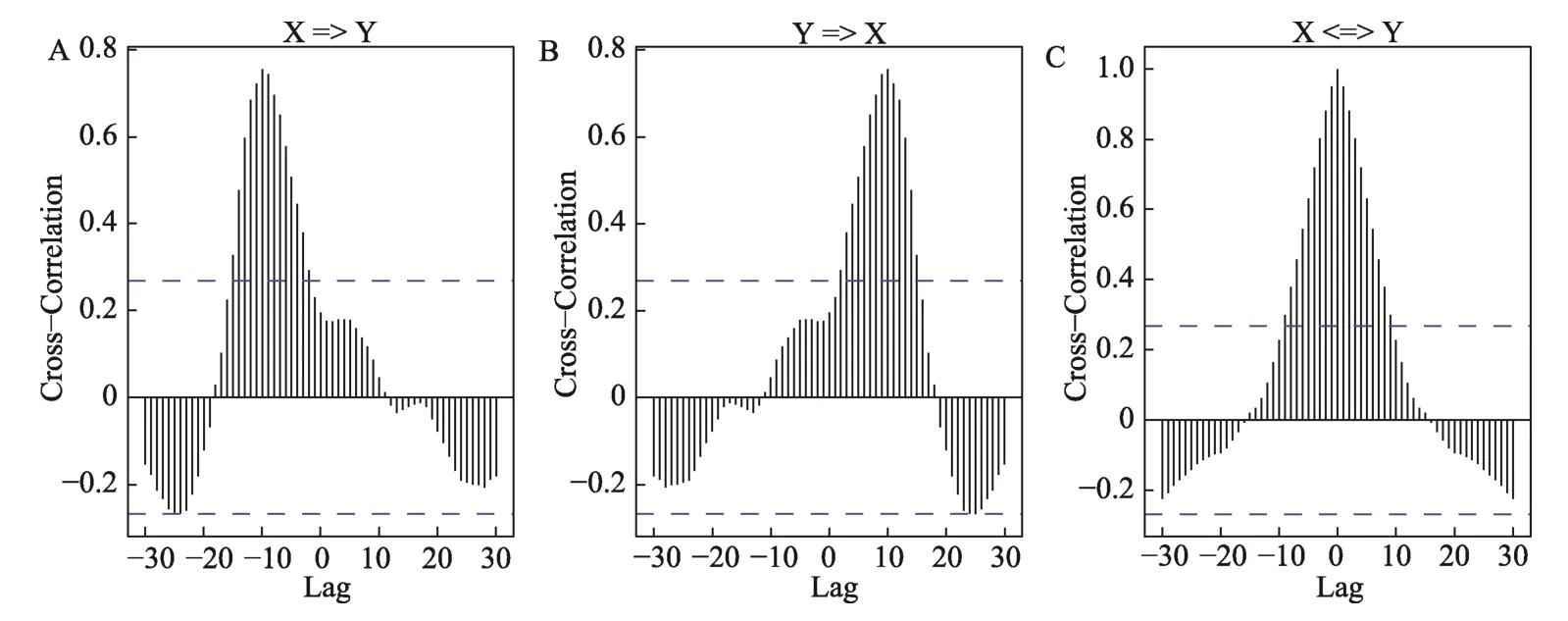
图1 交叉相关示意图
迄今,交叉滞后相关分析在社会变迁的研究中已经有很多应用。比如,有研究曾用交叉滞后相关分析来考察文化变量(如个体主义、文化松紧性)与社会生态变量等因素之间的跨时间共变关系(Caluori et al.,2020;Grossmann &Varnum,2015;Jackson et al.,2019;Xin &Xin,2017)。
3.3.2 格兰杰因果检验(Granger causality test)
交叉滞后相关分析只是对两个时间序列X 和Y 先后顺序的初步探索,尚未考虑某些混淆因素(如Y 自身滞后项与Y 当期数值的自相关),因此不足以作为最终结论。为了进一步确定X 和Y 是否存在时间顺序上的因果关系,还需要进行格兰杰因果检验(Granger,1969)。具体而言,格兰杰因果检验会首先以Y 为结果变量,以Y 的1~p 阶滞后项、X 的1~p 阶滞后项为预测变量(滞后阶数p可根据信息准则确定,一般不超过10),建立回归模型。该模型既包括Y 的自回归,也包括X 若干滞后项对Y 的回归。然后,使用F检验考察X 的滞后项对Y 的回归系数是否都为零,即相当于在控制了Y 的滞后项之后,考察X 滞后项对Y 是否有显著的预测作用,如果存在,说明加入X 的滞后项能够显著提升预测效果,进一步说明X 有助于预测Y 的变化,认为X 是Y 的格兰杰原因(Granger cause)。为了严谨起见,还可以进行反方向的格兰杰因果检验,如果Y 不是X 的格兰杰因果原因,则可以使原有结论更具有说服力。
需要注意的是,与其他时间序列分析方法一样,格兰杰因果检验也需要满足一个前提条件,即时间序列的平稳性。因此做格兰杰因果检验之前一般需要对原始时间序列进行平稳化(如Caluori et al.,2020)。而且,格兰杰因果检验揭示的仍然是一种时间先后的预测关系,这种关系仍然有可能是由第三变量引起的,并不属于严格意义上的因果关系,至多可以认为是真正因果关系的一个必要条件。
格兰杰因果检验在经济学中应用广泛,近年来,在社会变迁研究中的应用也越来越多。在一项旨在探讨自1990 年以来中国人的幸福感变迁趋势及其背后原因的研究中,Cai 等(2022)在明确了中国人幸福感的上升基本趋势后,进一步探讨了经济增长和幸福感变化之间的关系。他们首先进行了交叉滞后相关分析。结果显示,人均GDP可以显著提前预测幸福感,而幸福感却不能提前预测人均GDP,预示着人均GDP 的增长是中国幸福感提升的一个可能原因。随后,他们进一步进行了格兰杰因果检验。结果发现,在控制了幸福感的自回归影响后,人均GDP 依然可以预测1年、2 年和4 年后的幸福感,表明人均GDP 是幸福感的格兰杰原因。
3.4 多元时间序列分析:向量自回归(VAR)模型、基于VAR 模型的格兰杰因果检验
上面考察的是只有两个时间序列变量且假设其中一个为因、一个为果的情形。如果不事先假设因果,或者存在两个以上的时间序列变量,则需要采用向量自回归(vector autoregression,VAR)模型(Sims,1980),对多个时间序列变量的动态关系进行同时考察。
具体地,对于两个或多个平稳时间序列变量,VAR 建立的是一组时间序列回归模型。其中,每个回归模型的结果变量分别是各个时间序列变量,而预测变量是相同的,皆为所有时间序列变量的1~p 阶滞后项;滞后阶数一般可根据信息准则(如AIC)确定,年度数据的滞后阶数一般不超过 5(Box-Steffensmeier et al.,2014;Levendis,2018;Neusser,2016)。例如,对于3 个平稳时间序列X、Y、Z,建立3 个分别以X、Y、Z 为结果变量的回归模型,每个模型的预测变量都是 Xt-1~Xt-p、Yt-1~Yt-p、Zt-1~Zt-p;如果设定滞后阶数p=5,那么预测变量就一共有15 个。滞后阶数p 是VAR模型需要设置的主要参数,因此,一般也把向量自回归模型具体写为VAR(p)模型。此外,由于变量个数和滞后阶数的乘积等于VAR(p)模型每个回归方程的预测变量个数,两者都不能过大,否则回归方程会产生过多需要估计的参数,使模型估计的精确程度和有效性降低。
基于VAR 模型,研究者也可以进行多变量的格兰杰因果检验。与双变量的思路类似,基于VAR 模型的格兰杰检验同样使用F检验考察加入一个时间序列的若干滞后项是否能够显著提升对另一个时间序列的预测作用,如果统计显著,则说明前者是后者的格兰杰原因(Levendis,2018;Neusser,2016)。由此,可以基于VAR 模型对多个时间序列变量进行一系列的格兰杰因果检验,不仅统计效率更高,而且充分考虑了多元时间序列作为一个变量系统而可能存在的内部相互影响(Box-Steffensmeier et al.,2014)。实际上,以往研究进行的双变量格兰杰因果检验是VAR 模型格兰杰因果检验的一个特例;VAR 模型作为更普遍适用的多元时间序列分析方法,在最新的社会变迁研究已经有多个应用尝试。
在一项探讨2006~2014 年间美国房地产价格和开放性人格之间的共变关系研究中,Götz 等(2021)就采用了基于面板数据的面板向量自回归模型(panel vector autoregression,PVAR)。模型中,房地产价格和开放人格之间互为因果,互相交叉滞后预测。结果发现,房地产价格可以预测一年后的房屋购买者的开放人格水平,价格越高,购买者的人格越开放;但是,开放人格却不能预测房屋价格。在另一项研究中,Chan 等(2021)探讨了全球167 个国家社会流动性(向上流动)在2005 到2019 年间变化趋势及和教育私有化、GDP、收入不平等三个社会生态变量之间的关系。他们运用PVAR 估计四个变量之间的相互预测关系(包括同时预测和滞后的交叉预测)的同时,再通过格兰杰因果检验,进一步考察了上述三个生态变量是否是社会流动性的格兰杰原因。结果发现,教育私有化在部分国家会降低向上流动性(比如中国、新加波、哥伦比亚、约旦、菲律宾、印度尼西亚等),在另外一些国家却会增强向上流动性(比如德国、墨西哥、马来西亚等)。这些结果不仅表明教育私有化对社会流动性的决定性作用,还揭示这种作用随国家而异。
社会变迁对人的心理和行为的影响正在成为心理学的前沿热点之一,得到越来越多心理学家的关注(Muthukrishna et al.,2021;Cai et al.,2019;蔡华俭 等,2020;黄梓航,敬一鸣 等,2018;黄梓航 等,2021)。自新中国、特别是改革开放以来,中国经历了几十年的高速发展,社会发生了广泛而深刻的变化,探讨中国人的心理和行为的变化及其背后原因不仅具有重要学术价值,更对国家治理具有重要意义。为了促进国内学界对该领域的研究,本文从两个方面对相关研究方法进行了较为全面的介绍。
第一个方面涉及变迁研究中的常用研究设计。这些设计中,有的是基于跨时间的比较,有的是基于跨代/地区的比较;有的是基于群体数据,有的是基于个体数据;有的基于客观数据,有的基于调查数据。所有的方法都可以从某一个方面触及和社会变迁相关的两种效应(时间效应和时代效应)中的一种或两种,从而使得我们可以基于某种逻辑(历史演进或历史重构)对心理和行为的变迁规律进行推测。总体上,这些方法各有特点、各有优缺点。这意味着,我们在进行具体研究时,在方法的选取上要根据研究的目的、研究资源的多少、数据的可获得性和难度等选取恰当的方法。
鉴于每一种方法都是从不同角度触及和变迁相关的时间或时代效应,但同时又可能混淆着无关的效应,理想的方法是同时采用多种方法对同一个问题进行研究,相互取长补短,以寻求多视角的聚合证据。比如,关于中国人幸福感的变迁,我们可以同时采用档案研究(利用流行歌曲歌词中的积极和消极情绪词的变化)、横断历史元分析(对已发表的幸福感的文献按照时间维度进行定量分析)、跨时间对比(对不同时间点上获得的幸福感数据进行比较)、跨代研究(对不同年代或代际的差异进行对比)、跨地区对比(对发达地区和不发达地区民众的幸福感进行对比)、甚至追踪研究(对同一批被试在不同时间点的幸福感进行对比)。这样,我们就可以避免基于单一方法或单一来源的数据进行推论。
第二个方面涉及变迁研究中的常用数据分析方法。对此我们介绍了目前研究中常用的几种统计方法,包括传统的简单相关和回归分析,以及基于时间序列分析的交叉滞后相关分析、格兰杰因果检验。通过简单相关和回归分析,我们可以很快知道变迁的基本趋势、各种社会生态变化和结果变量之间的共变关系,大致可以推测导致变化的社会生态因素;通过交叉滞后相关分析,我们可以进一步推测已经揭示的共变关系可能的先后顺序;通过格兰杰检验,我们可以进一步排除自回归的影响,对潜在因果关系进行更为可靠的检验。但是,需要注意的是,现有的这些方法揭示的本质上都是一种相关关系;这种相关关系依然有可能是其他变量导致的。
此外,变迁研究中一个棘手问题就是年龄效应、时间效应和时代效应的分解和估计。对此,理论上虽然没有完美的方法可以彻底解决该问题,但是已经有大量的方法性研究,并提出了很多可能的分解和估计方法,比如局部限定法、两因素模型、内生因子法等(Bell,2020),不同的模型适用于不同的设计和数据。其中一种较新的、应用较广的就是年龄-时间-时代(Age-period-cohort,APC)模型(Yang &Land,2008,2013)。APC 模型可用于分析横断序列设计的数据。该模型把年龄作为个体内变量、时期和时代作为情境变量,个体嵌套在时间和时代中。以此为基础建立的两水平线性APC 模型中,个体年龄为第一水平的预测变量,时间和年代为第二水平的预测变量,因变量则为具有某一年龄、出生于某特定时代、在某一特定时间点的某心理变量。通过APC 模型分析,我们可以大概估计年龄、时期和时代效应。不过,该模型适用数据有限,且模型需要很强的假设,比如所有随机变量服从多元正态分布;当样本数据量较小或数据不平衡时,模型的参数估计和假设检验结果可靠性将降低。鉴于变迁研究中三种效应的分解和估计问题的复杂性,我们将另文专述。
需要指出的是,社会变迁及其对心理和行为的影响非常复杂,学界关心的问题远不止变化趋势和可能的原因,还有变迁的后果(比如,对经济的影响等)、变迁的过程和机制等,不同的问题研究方法也不尽相同。本文只是对和变迁趋势相关的常见研究设计和数据分析方法进行了介绍。关于变迁的过程和机制的常用研究方法,辛自强等已有专文介绍(辛自强,刘国芳,2012)。此外,国内还有研究者对一些更为特定的方法进行了详细介绍,比如,文化产品分析(丰怡 等,2013)、横断历史元分析(辛自强,池丽萍,2008)、利用互联网数据进行变迁研究(李永帅 等,2017)、社会变迁研究有关的各种数据资源(黄梓航,王可 等,2018)等,。期待本文和其他相关文章一起,能为国内的研究者开展社会变迁研究提供相对全面的方法参考,最终促进国内的社会变迁研究。
猜你喜欢格兰杰效应变量铀对大型溞的急性毒性效应核科学与工程(2021年4期)2022-01-12抓住不变量解题小学生学习指导(高年级)(2021年4期)2021-04-29懒马效应今日农业(2020年19期)2020-12-14也谈分离变量河北理科教学研究(2020年2期)2020-09-11应变效应及其应用中学物理·高中(2016年12期)2017-04-22分离变量法:常见的通性通法新高考·高二数学(2014年7期)2014-09-18榜单Advances in Meteorological Science and Technology(2014年3期)2014-03-02临终的医生与关怀的本意中国新闻周刊(2014年5期)2014-02-17格兰杰因果关系在复杂网络中的应用*浙江师范大学学报(自然科学版)(2013年4期)2013-08-06变中抓“不变量”等7则小学教学参考(数学)(2006年7期)2006-12-31 相关热词搜索:研究,心理学,视野,





