面向室内场景的主被动融合视觉定位系统
时间:2023-04-21 13:40:04 来源:千叶帆 本文已影响人
谢挺,张晓杰,叶智超,王子豪,王政,张涌,周晓巍,姬晓鹏*
1. 浙江大学CAD&CG国家重点实验室, 杭州 310058; 2. 中国船舶工业系统工程研究院, 北京 100094;3. 中讯邮电咨询设计院有限公司, 北京 100048
高精度的室内目标定位技术在虚拟现实、增强现实和机器人导航等领域具有重要的应用价值。按照传感器信号来源,常见的室内定位技术可分为基于Wi-Fi等无线信号的定位技术、基于惯性导航的定位技术、基于地磁的定位技术和基于视觉信息的定位技术。其中,基于Wi-Fi等无线信号的定位技术对设备和场地有较高要求;
基于惯性导航的定位技术只能通过惯性测量单元(inertial measurement unit,IMU)获取相对位置,无法获得绝对位置;
而地磁定位技术时间开销较大且精度不高。在室内环境中,由于图像数据存在细节丰富、易于获取以及部署快捷等天然优势,基于视觉的室内定位方法得到广泛关注。室内视觉定位系统可以利用易于获取的RGB图像,对已知目标进行精确位姿估计。
按摄像头部署方式,基于视觉的室内定位方法可分为主动式定位(移动观测视角)和被动式定位 (固定观测视角)两种。被动式定位方法利用部署在场景中的固定摄像头,通过检测图像中的目标关键点进行模板匹配,从而解算出目标的位姿数据。这种方案的优点是定位结果比较稳定,不易受到光照、模糊图像的影响,但由于观测视角的限制,无法处理场景中存在的物体遮挡情况。主动式定位方法则是利用固定在定位目标本身的摄像头,通过检测场景的特征点,并与事先构建的3维场景模型进行特征匹配来得到目标的位姿信息。这种方案的缺陷是过度依赖图像的纹理特征,对于纹理丰富、特征明显的场景可以得到比较准确的定位结果;
而对于纹理特征缺失的场景,如墙面等弱纹理区域,定位结果非常不稳定。
在特定应用场景,例如室内移动机器人作业,既可以通过室内固定的监控摄像头进行目标的被动式定位,也可以通过定位目标自身(移动机器人)的移动摄像头进行主动式定位,这两类方法的定位结果有一定的共同性,而采用单一的主动式或被动式定位方法,都存在场景适应能力不足、定位精度受限等问题。
针对这类应用场景,本文提出一种主被动融合的室内场景定位系统。首先,基于单目标检测深度学习框架,提出一种基于平面先验的物体位姿估计方法,利用室内场景中普遍存在的平面约束,对运动目标进行3自由度(degree of freedom,DoF)位姿估计;
其次,提出一个基于无损卡尔曼滤波(unscented Kalman filter,UKF)的主被动融合定位框架,对主动式和被动式定位模块得到的位姿结果进行融合,提升了室内场景下运动目标位姿估计结果的稳定性和精准性。为验证提出的主被动融合定位系统的性能,在仿真平台iGibson和真实室内场景进行实验。实验结果表明,本文提出的融合定位方法可以有效提升室内场景中移动目标的定位精度及准确率。
本文主要贡献如下:1)提出一个基于无损卡尔曼滤波的主被动融合室内视觉定位系统框架,可以有效解决弱纹理及遮挡条件下的室内移动目标的位姿估计问题;
2)提出一种基于平面先验的物体位姿估计方法,可有效提升室内场景中运动目标的定位精度。
视觉定位技术根据定位原理不同,可以分为被动式定位技术和主动式定位技术两种。
1.1 被动式视觉定位技术
被动式定位的目标是根据固定视角得到的图像进行目标的定位,并得到目标物体的6-DoF位姿数据。传统的单目标定位方法主要通过模板匹配技术获取目标的3维点位置信息,如基于图像的梯度响应图检测场景中的3维物体(Hinterstoisser等,2013),或基于模型边缘轮廓的形状描述子估计目标位姿(Zhu等,2014)。但传统方法对环境变化和物体遮挡关系比较敏感,无法处理结构复杂的图像。
随着深度学习的发展,卷积神经网络在复杂结构和环境变化的图像检测和识别领域展示出优秀性能,例如PoseNet(Kendall等,2015)使用卷积神经网络(convolutional neural network,CNN)直接回归目标物体的位姿数据,但受限于RGB图像的深度信息缺乏和庞大的解空间搜索规模,效果并不鲁棒。Schönberger等人(2017)对手工特征和深度学习特征的2D—3D匹配性能进行评估,肯定了深度学习在图像匹配定位上的优秀效果。PoseCNN(Xiang等,2018)则通过预测2维图像的深度图改善3维定位效果。也有一些方法通过离散化旋转空间将定位问题转化为分类问题(Sundermeyer等,2018)进行处理,从而提升姿态估计结果的精度。谢非等人(2020)基于端到端模型提出准确高效的机器人室内单目视觉定位算法。
基于目标关键点的定位方法可以得到更加稳定的定位结果,这类方法通过局部特征点检测提取目标关键点,然后基于2D—3D点的对应关系,利用RANSAC(random sample consensus)算法和PnP(perspective-n-point)算法求解得到物体位姿。一些方法基于随机森林预测3D坐标值(Michel等,2017),并利用几何约束改进生成2D—3D点的对应关系。DenseFusion(Wang等,2019)则基于RGB-D数据,使用网络对RGB图像特征和3D点云特征进行整合,得到RGB-D数据的像素密集特征表示,然后通过投票获取物体的6-DoF姿态。PVNet(pixel-wise voting network)(Peng等,2019)通过对关键点进行投票得到遮挡情况下的局部特征向量,从而缓解图像中存在的目标遮挡和隔断问题。
单目视觉定位的一个缺陷是由于视角限制,位姿估计精度对拍摄距离和遮挡比较敏感。针对这一问题,刘昶等人(2012)基于共面二点一线特征进行视觉定位,MLOD(multi-view labelling object detector)(Deng和Czarnecki,2019)用多视图目标检测方法进行目标定位,取得了出色效果。
1.2 主动式视觉定位技术
主动式视觉定位方法指的是通过自身携带的移动摄像头拍摄环境图像来定位自身的方法,依据拍摄的当前观测图像,查询数据库中存在的图像位置信息,进行图像匹配来完成定位。经典的主动式定位方法包含场景建图和图像检索两个阶段。首先通过3维重建方法获取场景的3维点云模型,然后将输入的查询图像与点云模型中的3维点建立对应关系,使用RANSAC算法解算出查询图像的位置。
近年利用图像检索算法(Torii等,2015)从场景图像数据库中检索近似图像,得到较准确的初始位姿成为主动式视觉定位的主流方法。InLoc(indoor visual localization)(Taira等,2018)利用稠密的图像匹配和视角一致性来提升室内定位结果精度,但其算法依赖于全局匹配,计算代价较高,系统实时性较差。HFNet(hierarchical feature network)(Sarlin等,2019)则提出将图像检索和局部特征提取融合到统一的网络框架中,以提升姿态估计算法的计算效率。
主动式定位方法通常依赖于图像的强纹理特征,对纹理结构丰富的区域,特征点匹配成功率较高,得到的定位结果也比较准确,但在一些弱纹理或特征不显著的区域上的定位效果往往较差。针对这一问题,可以通过加入基于轨迹的滤波算法(Sattler等,2017)或利用其他辅助信息来改善定位结果。有一些方法(DeTone等,2018)通过增强特征点检测的性能来提升定位精度。场景无关相机定位方法DSM(dense scene matching)(Tang等,2021)和KF-Net(Kalman filtering network)(Zhou等,2020)主要使用稠密场景匹配,在图像和场景间构造cost volume,通过CNN网络来估计稠密坐标。
1.3 数据融合定位技术
多传感器数据融合技术在导航中的应用比较广泛,通常结合卡尔曼滤波算法、图优化算法来实现多传感器输入下的高精度定位。卡尔曼滤波假定误差满足线性高斯分布,但实际系统并不满足线性近似假设。扩展卡尔曼滤波(extended Kalman filter,EKF)将非线性模型在状态估计值附近做泰勒级数展开,采用局部线性化方法获得状态估计。无损卡尔曼滤波基于无损变换(unscented transform,UT)对后验概率密度进行近似估计,可以有效解决非线性系统引起的滤波发散问题。
VINSMono(Qin等,2018)基于单目视觉里程计和扩展卡尔曼滤波,提出了一套视觉信息和视觉惯性单元(inertial measurement unit,IMU)融合的松耦合框架,具有完善和鲁棒的初始化及闭环检测过程,以适应室内外环境。Li等人(2017)基于GPS(global positioning system)和图像融合,实现了对智能车辆的高精度定位。Xue等人(2017)基于相机、激光雷达和地理信息系统(geographic information system,GIS)的融合定位方法,实现了无人车的障碍物感知和高精度自主定位。杨承凯等人(2009)探讨了多传感器融合中的卡尔曼滤波。
结合视觉和激光雷达、惯性测量单元等其他物理传感器的定位方法可以得到比较高的定位精度,但对于定位装置的要求也非常高,通常需要装配价格昂贵的传感器设备。因此,本文希望能够利用低成本的RGB摄像头,提出一套基于视觉的室内主被动融合定位系统以实现便捷、精准的室内目标定位。
本文提供了一个在特定应用场景(被动式定位技术与主动式定位技术的定位目标相同)可实现的系统性视觉定位解决思路,结合了被动式定位和主动式定位两种方式的优点,当遇到视角盲区和强遮挡情况时,会更多地倾向于主动式定位的结果,而当遇到图像弱纹理情况时,更多地倾向于被动式定位的结果。仿真实验和实物实验结果都印证了本文的思路和猜想。
提出的主被动融合室内视觉定位系统主要包含3个模块,即被动式定位模块、主动式定位模块和主被动融合模块,如图1所示。其中,被动式定位模块的输入为室内固定视角摄像头得到的RGB图像,输出为该图像包含目标的位姿数据;
主动式定位模块的输入为待定位目标视角拍摄的RGB图像,输出为该目标在3维场景中的位姿信息;
主被动融合模块负责融合被动式定位和主动式定位的定位结果,然后输出最终的位姿数据。

图1 主被动融合系统的整体框架
在场景定位中,本文定义全局坐标系为目标运动的水平面,这样直观且便于测量误差,而被动式定位和主动式定位结果都会转换到这一坐标系上。
2.1 被动式定位模块
被动式定位模块流程主要包括关键点检测与筛选、位姿估计与优化两个步骤,如图2所示。

图2 被动式方法定位流程图
2.1.1 关键点检测与筛选
本文使用卷积神经网络获取待定位目标的关键点信息。对固定视角输入的RGB图像,首先使用CenterNet(Zhou等,2019)提出的基于中心点的目标检测方法,构建网络模型,从图像中检测出目标的中心点和尺度信息,得到目标的2维边框,从原始图像中裁剪出来用于定位。然后,针对检测到的目标区域,基于预先定义的目标关键点信息,预测图像中对应于目标关键点分布的多幅热力图,每幅热力图都代表一个关键点位置的估计结果。在关键点检测过程中,采用网络输出的关键点热力图计算每个关键点的像素坐标及对应的置信度,并使用关键点置信度预先过滤掉一些错误的关键点,如图3所示。

图3 关键点检测与筛选示意图
在关键点检测网络模型训练中,通过预先定义的目标关键点3维位置,由其真实位姿值进行投影,得到关键点在图像上的像素坐标。
2.1.2 位姿估计与优化
对于室内场景中的运动目标,例如室内服务机器人,通常沿水平面进行移动,高度信息不会发生剧烈变化,即待定位目标处于高度已知的水平平面内。设物体系z轴与世界系z轴平行,则该物体在3维场景中的运动可以简化为3-DoF的位姿估计问题。利用这样的平面假设,可以缩小位姿估计的求解空间,提高其估计的稳定性和准确性。
假设摄像头固定,可以通过场景中设置的已知标记点得到固定摄像头在全局坐标系中的位置和姿态。在此基础上,可以将通过单目物体定位得到的物体相对于相机坐标系的位姿转换到全局坐标系中。图像中每个2维像素点对应的全局坐标系3维坐标值是固定的,可以根据目标的2维框中心位置来估计定位目标的位姿初值(x0,y0)。
给定一组关键点的2D—3D对应关系,通过最小化目标函数可以得到物体在3维平面上的坐标(x0,y0),目标函数为
(1)
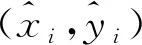
为避免式(1)的优化过程陷入局部最优,本文对(x0,y0)和目标对象的初始朝向角θinit进行初始化,以2维候选框的中心坐标(x0,y0)代表目标的中心坐标,通过相机成像模型,并假设Z=0。因此,可以根据投影方程计算出目标中心在世界坐标系位置的初始值(Xinit,Yinit),具体为
(2)
式中,K∈R3×4为相机内参矩阵,T∈R4×4为世界坐标系相对于相机坐标系的位姿,Zinit=0。
接下来,计算目标对象的初始朝向角θinit。
朝向角初始估计值θinit的取值范围为[0°,360°),将解空间以k°为步长进行采样,可计算出360/k组重投影误差,从中选取使重投影误差(如式(1)所示)最小的θinit作为初始朝向角。
位姿优化过程以位姿参数为待求解参数,以初始位姿为初始值,通过最小化重投影误差得到目标的最终位姿数据。
2.2 主动式定位模块
主动式方法定位流程包含3维场景恢复和场景特征点定位两个阶段,如图4所示。

图4 主动式方法定位流程图
主动式定位以场景地图为先验,类似于SLAM(simultaneous localization and mapping)系统中的重定位部分。在定位过程中,用采集的图像数据(定位目标携带的移动摄像头拍摄)匹配场景地图,获得的是相对于场景地图的位姿,而场景地图是预先对齐到全局坐标系的,因此主动式定位能获取定位目标在全局坐标系中的位姿。
2.2.1 3维场景恢复
3维重建的场景恢复过程主要基于运动恢复结构(structure from motion,SfM)技术。首先通过特征提取和特征匹配算法得到场景不同视角下图像之间的关联,初始选择两个基线距离较大且匹配较多的图像对进行重建,通过初始重建的3维点对其他图像帧进行定位。对新增的注册帧重新三角化出更多的3维点,然后不断迭代直到恢复出所有的图像位姿和点云表示的3维场景模型。
在完成场景的3维重建后,将场景地图对齐到全局坐标系。选取一些固定的标记点采集对应位置的图像,通过直接测量的方式获取标记点对应的全局坐标系3维坐标,然后将对应图像通过特征提取、与场景地图数据的特征匹配以及PnP算法得到在场景地图坐标系中的3维坐标,使用Umeyama算法(Umeyama,1991)计算得到两个坐标系之间的变换矩阵。
2.2.2 场景特征点定位
对输入的待定位图像,首先对其进行局部特征提取,并与已恢复场景地图中的局部特征进行匹配,得到待定位图像中2维局部特征位置与场景模型中3维结构之间的几何映射关系。然后在图像2D特征点和场景中3D特征点匹配基础上,通过求解PnP问题,得到该图像对应目标对象的6-DoF位姿信息。
2.3 主被动融合定位模块

(3)
系统的状态方程和观测方程可以表示为

(4)
(5)
式中,Xk为第k时刻目标的状态变量,包括位置、速度和加速度等,Uk为系统噪声,Qk为系统噪声分布的协方差,Wk为观测噪声,Rk为观测噪声分布的协方差,观测向量Zk为第k时刻主/被动式定位方法的预测定位结果(xk,yk)。
使用无损卡尔曼滤波算法将被动式预测定位结果与主动式预测定位结果进行非线性融合,根据式(3)和式(4),实际系统的状态方程可以表示为
Xk+1=f(Xk,Uk)=f(Xk)+Uk
(6)
根据式(5),观测方程可以表示为
Zk=h(Xk,Wk)=HXk+Wk
(7)
式中,初始噪声分布情况根据训练数据集中的样本采样估计、统计预测值和真实值的误差分布情况得到,包括被动式定位系统噪声Qp、观测噪声Rp和主动式定位系统噪声Qa、观测噪声Ra,即

主被动定位的结果按时间整理成观测值队列,按顺序加入到融合定位的滤波系统中,分别按照各自的噪声分布更新协方差矩阵和状态向量。
具体融合定位实现过程如下:
1)求初始状态均值和方差矩阵
(8)

2)通过UT变换,获取状态量采样点和对应权值,各采样点可以表示为
(9)
各采样点对应的权值可以表示为
(10)


(11)
式中,γi,k为采样点集通过观测函数得到的观测点集。
4)计算卡尔曼增益Kk+1,更新协方差PX,k+1和状态向量Xk+1,得到状态转移方程
(12)
将式中状态向量Xk+1包含的坐标值作为k+1时刻主被动融合定位的位置坐标。至此,完成了基于无损卡尔曼滤波的主被动融合定位方法。
数据融合的过程中,观测值来自于被动式定位和主动式定位的定位结果,共用同一个状态向量进行更新,但是被动式定位和主动式定位有各自的协方差矩阵。状态向量更新时,先判断观测数据来源是被动式定位还是主动式定位,选择协方差矩阵,然后对主被动定位方法得到的初步定位结果采用阈值筛选的方法去除偏差较大的观测值,得到有效观测。
对于被动式定位结果,基于重投影误差和关键点置信度进行评价和筛选,误差函数为
(13)

对于主动式定位结果,基于检测到的特征点数量和匹配点数量比例进行评价和筛选,误差函数为
(14)
式中,nsift为图像中检测到的SIFT(scale-invariant feature transform)特征点数量,ninliers为匹配到场景3维点的图像特征点数量。
3.1 实验平台与数据
为验证提出的主被动融合方法的有效性,本文分别在仿真平台和真实场景进行实验。仿真数据和真实环境获取的数据示例如图5所示。

图5 仿真数据和真实数据示例
本文在室内实际场景中利用Turtlebot3和Realsense采集图像数据进行实物实验,共生成10组数据,其中5组样本作为训练数据,用于被动式定位的模型训练以及主动式定位的场景3维重建,其余5组用于模型测试。其中,物体位姿定位的真实值(ground truth)根据在地面标记的记号点利用直尺直接测量得到。
3.2 评价标准
在算法评估方面,本文使用平均定位精度和定位准确率作为量化指标。
平均定位精度(average accuracy)指测试集中每个样本的定位结果到真实值(ground truth)的欧氏距离均值。具体为
(15)

定位准确率指能达到指定定位精度的正确样本占所有样本的比例。实验设置了小于15 cm、小于10 cm和小于5 cm三段范围的准确率指标来定量评估不同算法的定位精度。
3.3 网络参数设置
被动式定位方法中目标检测的网络框架采用Resnet-18,关键点检测网络框架采用Dla-34。模型训练输入的图像分辨率为512 × 512像素,批大小(batch size)设置为8,学习率设置为0.000 1。
3.4 仿真实验结果
在仿真实验平台上的可视化结果如图6所示,其中蓝色轨迹为iGibson记录真实值,红色轨迹为不同定位方法输出预测值,黄色区域为场景中固定视角的摄像头。

图6 仿真环境被动式/主动式/融合定位方法可视化结果
从定位轨迹结果可以看到,被动式定位方法的特点是在固定摄像头靠近中心的视野区域定位精度较高,而对于偏离视野中心距离的区域以及存在较严重遮挡的区域,其定位精度会严重下降。主动式定位方法对于纹理贫乏、特征不明晰的图像定位效果较差,其轨迹吻合度相对于被动式定位方法精度要差,但不容易产生较大估计误差,具备比较好的稳定性。经过UKF融合后的结果能准确恢复机器人的运动轨迹,对于主/被动存在定位误差部分进行了有效修正,且其轨迹的平滑程度和鲁棒性都得到了明显提升。
表1给出了不同算法在仿真数据集上的定位精度指标。从定位精度评估结果可以看到,基于UKF的主被动融合定位方法在平均定位精度和准确率上有明显提升。与SSD-6D的方法相比,被动式定位方法的平均定位精度和准确率都要高出一些,主要优势来自平面场景的3自由度优化。与基于EKF的融合定位方法相比,平均定位精度基本一致,但10 cm/5 cm的准确率有明显提升,特别是对遮挡比较严重的区域有更好的定位效果。

表1 仿真数据集定位结果
仿真实验结果表明,本文提出的主被动融合定位方法可以在仿真场景中实现cm级的精准定位,平均定位精度为2.01 cm,误差在10 cm内的准确率可以达到99.0%以上。
3.5 真实场景实验结果
为进一步验证本文方法的可用性,在真实室内场景的实物数据集上对不同算法的定位精度进行测试,结果如表2所示。从定位结果可以看出,基于UKF的主被动融合定位方法在平均定位精度和准确率上均取得了最优结果。图8给出了实际场景的定位准确率曲线,可以看到,在定位准确率上,基于UKF的方法相比主被动定位方法和EKF融合方法都有一定提升。

表2 实物数据集定位结果
真实场景的实验结果表明,主被动融合视觉定位系统能有效降低固定视角下被动式定位算法由于视角局限性、物体遮挡等外界干扰,同时可以有效克服单帧的定位算法稳定性不足、随机误差大的缺陷。本文提出的主被动融合定位方法同样能够在真实室内环境中实现cm级的目标精准定位,误差在10 cm内和15 cm内的准确率分别为93.1%和97.1%。
本文针对室内移动机器人作业等特定应用场景,提出了一个基于无损卡尔曼滤波的主被动融合室内视觉定位系统框架,与现有的视觉定位算法相比,能够以较低设备成本实现室内场景中高精度的目标定位结果,并在遮挡、目标丢失等复杂环境因素干扰下展示出鲁棒的定位性能,实现室内场景的纯视觉cm级精准定位。在仿真和实物环境下都进行了测试和验证,实验结果表明,定位系统具备很高的定位准确率和鲁棒性,能够用于多种场景。
但是,本文的研究工作还存在不少可以改进的地方。一方面,单目视觉定位方法存在对物体先验模型的依赖性,在无先验条件下进行定位是一个难题,而基于机器学习的定位方法需要大量的标注数据,如何对原始数据进行快速智能标注也是一个需要解决的问题;
另一方面,从数据融合算法的角度看,本文方法主要是在数据级融合和特征级融合上展开,在更高一层的目标级融合研究上还存在一些欠缺。
在未来工作中,将继续深入研究如何与视觉里程计等SLAM方法进行更深层次的数据融合,实现不同场景的模型迁移,将数据融合的系统定位算法应用于更加广阔的场景。
猜你喜欢被动式位姿定位精度北斗定位精度可达两三米军事文摘(2023年4期)2023-04-05被动式音乐疗法改善脑卒中后睡眠障碍的研究进展老年医学研究(2021年5期)2022-01-19被动式节能在住宅建筑设计中的应用分析建材发展导向(2021年24期)2021-02-12GPS定位精度研究智富时代(2019年4期)2019-06-01GPS定位精度研究智富时代(2019年4期)2019-06-01组合导航的AGV定位精度的改善测控技术(2018年4期)2018-11-25被动式低能耗建造技术探析江西建材(2018年2期)2018-04-14基于共面直线迭代加权最小二乘的相机位姿估计光学精密工程(2016年5期)2016-11-07基于CAD模型的单目六自由度位姿测量光学精密工程(2016年4期)2016-11-07简化供暖在被动式公寓的应用制冷技术(2016年4期)2016-08-21 相关热词搜索:定位系统,被动,融合,





