基于EEMD与CNN模型的多标签负荷识别方法
时间:2023-04-21 21:30:06 来源:千叶帆 本文已影响人
程志友, 程安然, 李 悦, 姜 帅
(1. 教育部电能质量工程研究中心, 安徽大学, 安徽 合肥 230601;
2. 安徽大学互联网学院, 安徽 合肥 230039)
非侵入式负荷监测(Non-Intrusive Load Monitoring, NILM)技术为居民提供负荷内部各用电设备的耗能信息,通过耗能信息、电能质量、分时电价、电能计量等综合信息,电力用户可以采取有效措施来减少耗能,同时非侵入式电表可以很容易地集成到现有建筑中,而不会给电力消费者造成不便,近年来已成为国内外学者的研究热点[1]。NILM技术依赖于信号处理和机器学习方法,通过单个智能电表、电流电压传感器等点源监测的聚合功率数据来推断在建筑中运行的终端设备,估计独立负荷的功耗并进行负荷状态的有效识别[2]。
NILM的识别精度取决于负荷特征的差异性,因此特征提取对NILM至关重要。特征提取可以看作是从原始电压信号和电流信号中获取重要信息的信号处理过程,相关学者提出了多种方法获得需要改进的特征来提高NILM性能。Hart首先提出使用功率的变化作为负荷特征,精度可达到80%,但对于功耗相近的设备,识别精度则大大降低[3]。高采样频率提供如谐波、V-I轨迹等高频特征,刘恒勇等人通过提取用电器稳态电流信号,经过傅里叶变换提取谐波分量作为负荷特征,并将该负荷特征作为循环神经网络(Recurrent Neural Network, RNN)模型的输入,实验表明所提取的特征值能将用电器成功识别[4]。然而该负荷特征提取需要较高的采样频率和较大的数据存储容量,增加了硬件设备的成本。凌家源等人通过应用卷积神经网络(Convolutional Neural Networks, CNN)模型进行负荷识别,利用CNN可以自动提取特征的特点,使用特征丰富的高频电流数据作为输入,取得了较好的识别效果[5]。文献[6-10]表明,将V-I轨迹转化为图像表示,并将其作为机器学习分类器的输入,可以提高分类性能。然而文献中提出的方法均使用单标签学习,忽略了多个设备可以同时运行的事实,以及设备使用之间的依赖关系。实际应用场景中,家用电器种类繁多且多种负荷同时运行的情况比较常见,因此多标签学习是传统NILM方法的一种可行的替代方法[11-15]。文献[14]中对低采样功率测量的多标签分类和多标签元分类框架进行了广泛的调查。文献[16]提出利用各用电设备的稳态电流谐波特性,建立用电设备特征标签,然后采用弹性后向反馈(Resilient back PROPagation, RPROP)神经网络,训练多种设备组合,进行多标签负荷辨识。文献[17]提出改进鸡群算法作为负荷识别算法,以家用电器稳态电流基波和谐波作为负荷特征参数进行多标签识别。但文献[16,17]均需人为选取特征进行识别,且选取特征参数有限。
针对以上多标签负荷识别方法依赖于特征量的选取,本文提出了一种基于集合经验模态分解(Ensemble Empirical Mode Decomposition, EEMD)结合CNN模型的负荷识别方法,首先从检测到事件的聚合测量数据中提取单周期稳态电流特征,随后应用EEMD将该电流特征分解为两种目标模态分量,接着应用欧氏距离相似度函数将分解后的模态转化为二维矩阵表示,通过CNN多标签分类器自动提取矩阵的有效特征。最后在PLAID(即插即用设备标识)数据集上对所提出的方法进行了实验验证,结果表明,基于EEMD与CNN模型的负荷识别准确率较高,能够有效地实现多标签负荷识别[18]。
由于提取到的电流信号具有非平稳和非周期性,传统的傅里叶变换不能描述信号某一频率的出现时刻,因此有学者提出了多种时频分析方法,如短时傅里叶变换和小波变换等,但其基本思想都是根据傅里叶分析理论,对非线性非平稳信号的分析能力不足,受限于Heisenberg不确定原理。经验模态分解(Empirical Mode Decomposition, EMD)是由Huang等人于1998年提出的一种新型自适应信号时频处理方法,适用于非线性非平稳信号的分析处理[19]。然而EMD的分解过程中易发生模态混叠问题,模态混叠问题使得特征提取、模型训练、模式识别变得困难,本征模态函数(Intrinsic Mode Function, IMF)失去了单一特征尺度的特征。为解决模态混叠问题,Huang等人在2009年提出通过加噪声辅助分析的集合经验模态分解理论,其本质是对信号进行平稳化处理,不需要人为选择基函数和分解层数,利用其分解结果可以准确有效地把握原数据的特征信息,不仅能有效抑制经验模态分解中出现的模态混叠现象,得到更有意义的IMF分量,而且能将原一维观测信号分解成多维,为实现信号的盲源分离创造条件[20]。
EEMD算法步骤如下:
步骤1:在采集到的目标信号x(t)中添加均值为零、标准差为常数的随机白噪声gi(t),得到含噪信号为:
xi(t)=x(t)+gi(t)
(1)
式中,gi(t)为第i次加入高斯白噪声的信号,加入的高斯白噪声大小会直接影响信号EEMD分解效果,一般取gi(t)的标准差为采集信号标准差的0.1~0.4。
步骤2:对xi(t)分别进行EMD处理,得到的IMF分量记为dij(t)和余项ri(t)。
步骤3:重复步骤1和步骤2,N次后,利用不相关随机序列统计均值为0的原理,将步骤2对应的IMF分量进行总体平均运算,从而消除多次加入高斯白噪声对真实IMF分量的影响,最后得到EEMD分解后的IMF分量。
(2)
式中,dj(t)为目标信号x(t)进行EEMD处理后得到的第j个IMF分量。当N越大,对应的白噪声IMF分量的和将趋于0,此时EEMD分解的结果为:
(3)
式中,r(t)为最终的残余分量,代表信号的平均趋势。通过EEMD理论可以把任意一个目标信号x(t)分解为若干个IMF分量dj(t)和一个残余分量r(t),本文中噪声信号标准差取0.3,N取300。

(4)


3.1 从聚合测量中进行特征提取
本文研究对象为家用电器负荷,其状态改变对系统冲击很小,因此设备状态切换30周期后可认定处于稳定状态[21]。图1为根据标签数据得到的风扇与吸尘器在不同时刻开启同时运行以及最后分别关闭的实例样本。

图1 不同事件的聚合电流信号Fig.1 Aggregate current signals of different events
为获得家用电器稳态运行数据,对选取的设备根据事件标签中的时间戳,在短时间窗口测量到的高频聚合电压和电流数据中找到事件发生的时间点,从样本标签中最后一台设备开启后30周期开始测量Nc个完整稳态周期电压和电流数据(这些周期均在电压过零点处对齐),其中数据集采样频率fs=30 kHz,电表采集频率f=60 Hz,一个周期内的采样点数T=fs/f=500,接着将这些周期内相应索引点的值累加取平均,从而获取到一个周期内的稳态电流特征。计算公式如下:
(5)
(6)

图2为不同设备稳态运行对应的电流特征。
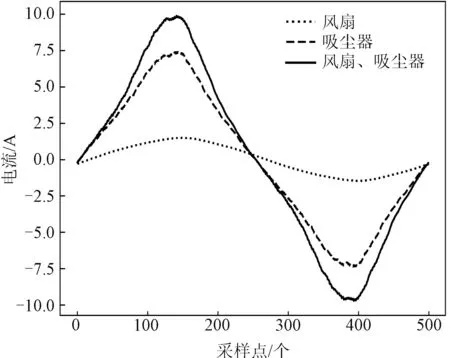
图2 不同稳态电流特征Fig.2 Different steady-state current features
3.2 基于EEMD的特征预处理
对提取到的电流特征进行EEMD,由于分解后的模态数量不一致,大部分样本的电流波形在分解到第5个模态后无法进行分解,且前3种模态频率过高,含有用信息量较少,为了尽可能在保留原始波形特征的条件下捕捉到其高频细节,实验目标选取包含工频的第4、第5模态分量(对应图3的i(t)m1,i(t)m2)。通过对空调、紧凑型荧光灯、咖啡机等12种类型设备的电流信号进行EEMD处理并归一化,得到如图3所示的结果。
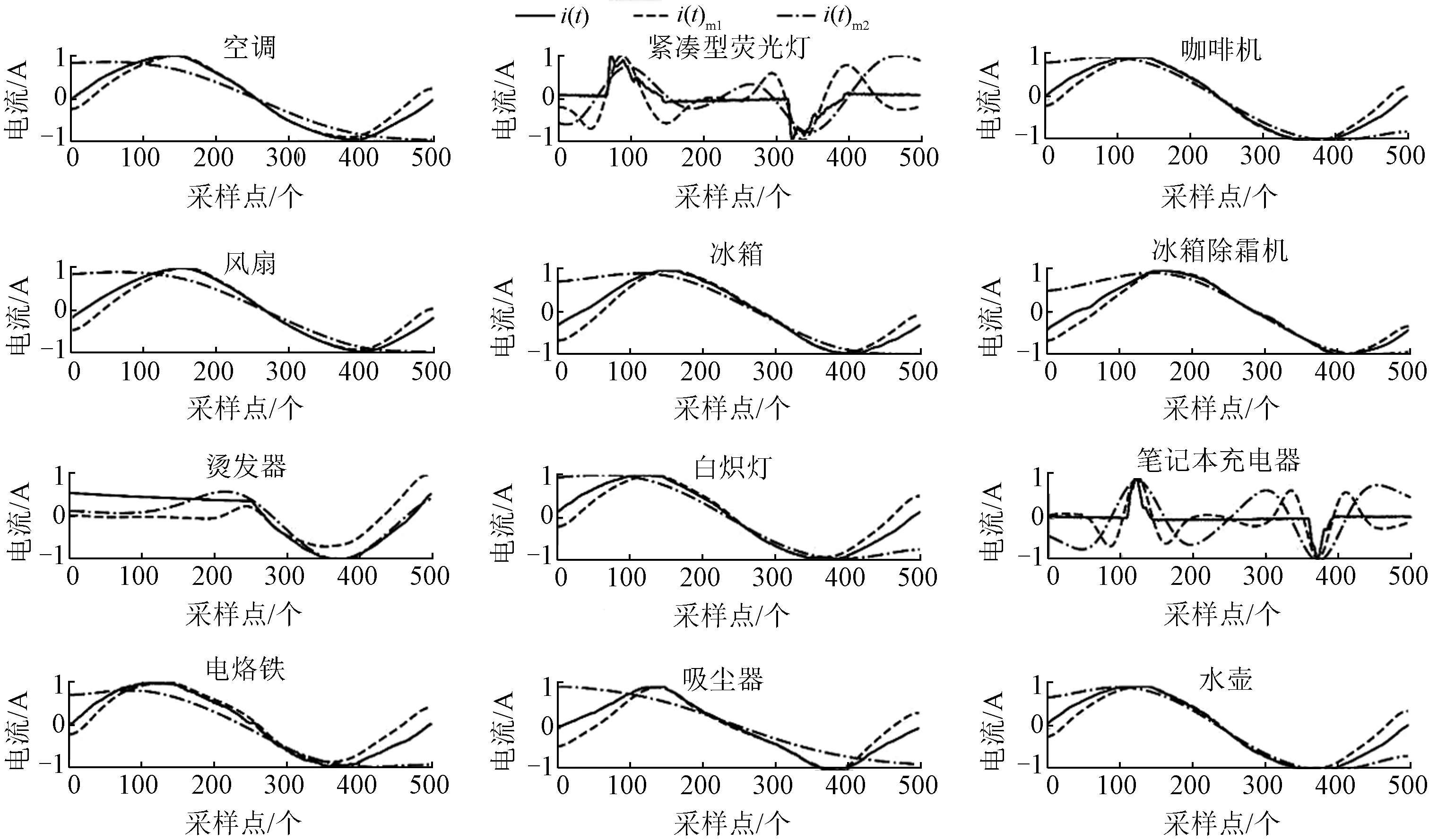
图3 归一化电流及其相应的第4、第5模态电流Fig.3 Normalized current and its corresponding fourth and fifth mode currents
从图3可以观察到,即使对于紧凑型荧光灯和笔记本充电器等非周期负载电流设备,其电流特征对应的第4模态分量也接近纯正弦波,通过EEMD后的两种模态电流特征的结合使得每种类型设备通常表现出一致又独特的特点,为后续进行多标签负荷识别的实验提供条件。


图4 ω取不同值时的识别性能和训练时间Fig.4 Recognition performance and training time with ω taking different values
为进一步提高不同类型设备对应模态电流特征的唯一性,将欧式距离相似度函数du,v=‖i(t)u-i(t)v‖2应用于EEMD后的模态分量,该函数通常用来测量两个数据点间的相似性或相关性,且欧式距离相似性函数被广泛用作机器学习算法的预处理步骤[22],距离相似度矩阵Dω,ω表示欧几里得空间中一组ω点的间距。
(7)
图5为紧凑型荧光灯和笔记本充电器同时运行时提取到的电流特征以及该电流特征经EEMD后的两种目标模态。
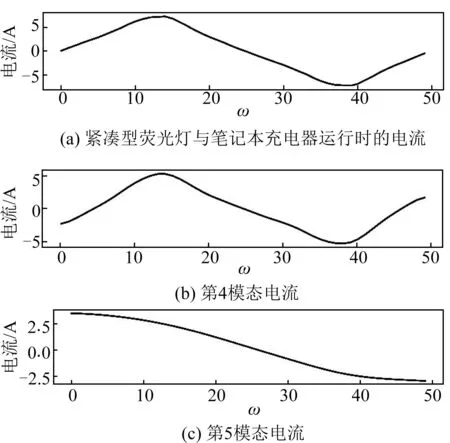
图5 紧凑型荧光灯与笔记本充电器运行时的电流及EEMD后的两种模态电流Fig.5 Compact fluorescent lamp and notebook charger operating current and two modes of current after EEMD
图6展示了图5中的电流特征通过欧式距离相似度函数转化成的2维矩阵图像表示,其中H,ω为维度,通过图6可以观察到,两种模态电流对应的距离矩阵比原始电流对应的距离矩阵所含信息量更丰富,有利于后续CNN模型的学习。

图6 图5电流对应的距离矩阵Fig.6 Distance matrix of current showing in figure 5
3.3 多标签建模


图7 CNN多标签分类器结构Fig.7 Structure of CNN multi-label classifier
为学习该模型参数,使用标准反向传播来优化预测的Softmax分布和基于每个输入特征的多标签目标之间的交叉熵,联合交叉熵损失隐式地捕捉了标签之间的关系:
(8)

实验采用了多标签分层10折交叉验证方法,这种评价方法提供了多标签的分层随机折叠,保存了标签在每次折叠中的百分比,同时通过多次划分样本中训练集和测试集的大小来训练该多标签分类器,每运行一次,取总样本的p份进行100次迭代训练,并在该样本剩下的1-p份中进行测试,其中p∈[0.1,0.9]。本文所提方法流程框图如图8所示。

图8 方法流程框图Fig.8 Flow diagram of method
4.1 数据集
本文利用来自美国加州55个家庭中12种不同类型的设备负载电流与电压测试值的PLAID数据集进行实验验证,数据集主要包含了两部分内容,第一部分是高频采集的电压及电流数据,采样频率为30 kHz,第二部分标记了电器种类,电器切换时刻以及采样时长等标签数据,共1 478个实例样本,其中单一负荷样本采样时长在4~6 s,含多个负荷开启样本采样时长在10~20 s。首先选取该数据集中含1~3个设备状态转换的电流和标签样本,随后根据3.1节所述特征提取方法,得到最终用于训练及测试的1 154个样本,其中每个样本的采样时长为(1/60)×20 s=(1/3)s。
通过图9可以看出,电烙铁的样本最多,冰箱除霜机的样本最少,其余10种负荷的样本居中;
图10可以观察到,单一设备的样本占总样本比例最大,达到674例,含多个设备运行的样本数量较少,分别只有413例和67例。

图9 设备类型分布Fig.9 Distribution of device type

图10 设备数量分布Fig.10 Distribution of device’s number
4.2 评价指标
实验采用基于标签和基于实例的度量标准来定量评估分类性能,即基于实例的F1度量(F1-eb)和宏观-平均的F1度量(F1-marco)。
F1-eb用来度量正确预测标签与真实和预测标签总和的比例:
(9)
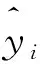
F1-marco源自F1-score,度量所有标签上基于每类标签的F1-score平均值,该指标被广泛应用于多分类任务中,定义如下:
(10)
式中,FPi为第i类负荷被分类为运行状态而实际为关闭状态的数量。
4.3 实验结果分析
为验证本文所提方法在单一负荷识别上具有较好的识别效果,实验首先针对单一负荷的样本进行设备识别,同时提取了另外4种用于负荷识别的特征进行对比分析,依次是V-I二进制图像(如文献[8]所述,首先获取一个稳态周期下的电压、电流波形,构建T×T维矩阵并将生成的图片划分到ω维度的网格栅栏,将含有像素的网格栅栏指定为1,反之指定为0,最终得到ω×ω维包含0与1的2维矩阵)、单周期稳态电流波形、电流经EEMD后的目标模态分量(以下简称EEMD电流)、电流对应的欧式距离矩阵(以下简称距离矩阵)。表1为本文所提方法与上述4种特征结合CNN模型进行单一负荷识别的F1-eb度量结果。

表1 各负荷的F1-eb度量Tab.1 F1-eb measurement of each load
从表1可以看出,针对大多数类型设备,将提取到的电流通过EEMD后再输入到CNN模型中进行单一负荷识别,都不同程度地提高了负荷识别率,可以看出EEMD在特征预处理环节的重要性,而显而易见的是,本文所提特征在此基础上更进一步提高了单一负荷的识别率,在咖啡机和冰箱除霜机上的F1-eb度量均为1;
除紧凑型荧光灯、空调、笔记本充电器、吸尘器4种家电负荷外,本文所提方法在识别其余9种负荷上的F1-eb值最高,均优于其他4种方法。
同时,表2还对比分析了上述5种特征在进行单一负荷识别上的F1-marco值。

表2 基于5种特征提取方法的F1-marco度量Tab.2 F1-marco metrics based on five kinds of feature extraction method
从表2中可以看出,V-I二进制图像结合CNN模型识别的F1-marco度量只有0.826,本文所提方法的F1-marco度量达到0.951,值得注意的是,距离矩阵特征进行单一负荷识别的F1-marco值达到0.938,仅次于本文方法,由此可见距离矩阵特征较电流特征更有助于CNN模型进行单一负荷识别的学习。
本文主要探究的是所提方法识别多台设备的性能,因此针对图10中的样本分布进行多标签负荷识别,得到的实验结果见表3。

表3 识别多个设备的准确率Tab.3 Accuracy of identifying multiple devices
可以看出,基于V-I二进制图像特征的负荷识别方法在识别单一负荷时的准确率最低,为90.5%,而本文所提方法的准确率高达98.5%;
采用电流特征进行识别多个设备的准确率最低,仅为34.6%和6%,基于EEMD电流特征的识别准确率为53.8%、23.9%,有较大幅度提升,由此可见,EEMD在多标签负荷识别率方面,具有良好的改善作用,而本文所提方法的准确率分别为78.9%、40.3%,较电流特征提高了4.3%和3.4%,均优于其余4种负荷特征,有力地验证了本文所提方法在多标签负荷识别上具有良好的识别效果。
表4进一步对比了本文方法与近几年的NILM相关文献所提方法进行负荷识别所获得的F1-marco度量,尽管有些方法所用数据集和模型学习特点不尽相同,但与表4中各项实验条件相同的第2种方法所获得的F1-marco得分对比,本文所提方法的F1-marco值较之提高了1.1%。

表4 不同方法性能对比Tab.4 F1-marco metrics based on different methods
本文提出了一种基于EEMD与CNN模型的多标签负荷识别方法,实现了对用户负荷有效的非侵入式监测,首先从高频电压和电流聚合测量数据中提取单周期稳态电流信号,随后应用EEMD理论,该方法将电流特征分解为多个模态分量,从中选取2种目标模态分量,随后应用欧氏距离相似度函数将分解后的电流信号转换为2维矩阵表示,作为CNN多标签分类器的输入。通过PLAID聚合数据集的实验结果表明,本文所提出的方法能较准确地从聚合测量数据中识别多台设备,具有较高的家电负荷识别准确率。
猜你喜欢分量标签模态帽子的分量基层中医药(2021年12期)2021-06-05一物千斤智族GQ(2019年9期)2019-10-28无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30论《哈姆雷特》中良心的分量英美文学研究论丛(2018年1期)2018-08-16不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09车辆CAE分析中自由模态和约束模态的应用与对比广西科技大学学报(2016年1期)2016-06-22标签化伤害了谁公民与法治(2016年10期)2016-05-17国内多模态教学研究回顾与展望湖北经济学院学报·人文社科版(2015年8期)2015-12-29科学家的标签少儿科学周刊·少年版(2015年2期)2015-07-07基于HHT和Prony算法的电力系统低频振荡模态识别上海电机学院学报(2015年4期)2015-02-28 相关热词搜索:负荷,识别,模型,





